Virtual Memory¶
Background¶
- only part of the program needs to be in memory for execution
-
allow memory to be shared by several processes - better IPC performance
-
Code needs to be in memory to execute, but entire program rarely needed or used at the same time
-
Virtual memory is larger than physical memory. 需要注意的是虚拟地址只是范围,并不能真正的存储数据,数据只能存在物理空间里。
Virtual-address Space
共享libc

Demand Paging¶
- Demand paging brings a page into memory only when it is demanded
只有用的时候才分配,省内存 但这时使用就会浪费时间
用时间换空间
-
demand means access (read/write)
-
if page is invalid (error) ➠ abort the operation
-
if page is valid but not in memory ➠ bring it to memory
- page fault
-
What causes page fault?
-
User space program accesses an address
-
Which hardware issues page fault?
-
MMU
-
Who handles page fault?
-
Operating system
-
Demand paging needs hardware support
- page table entries with valid / invalid bit
- backing storage (usually disks)
- instruction restart
What causes page fault?¶
malloc 最后也会调用 brk(),增长堆的大小。
VMA 是 Virtual Memory Area,brk() 只是增大了 VMA 的大小(修改 vm_end),但是并没有真正的分配内存,只有当我们真正访问这个地址的时候,会触发 page fault,然后找一个空闲帧真正分配内存,并做了映射。
- 蓝色代表virtual address,绿色代表物理帧
- 在virtual address中,upper part存着kernel,lower part存着user
- on 32-bit, the split is at
0xC0000000,高于此就是kernel,低的就是user,3G for user,1G for kernel
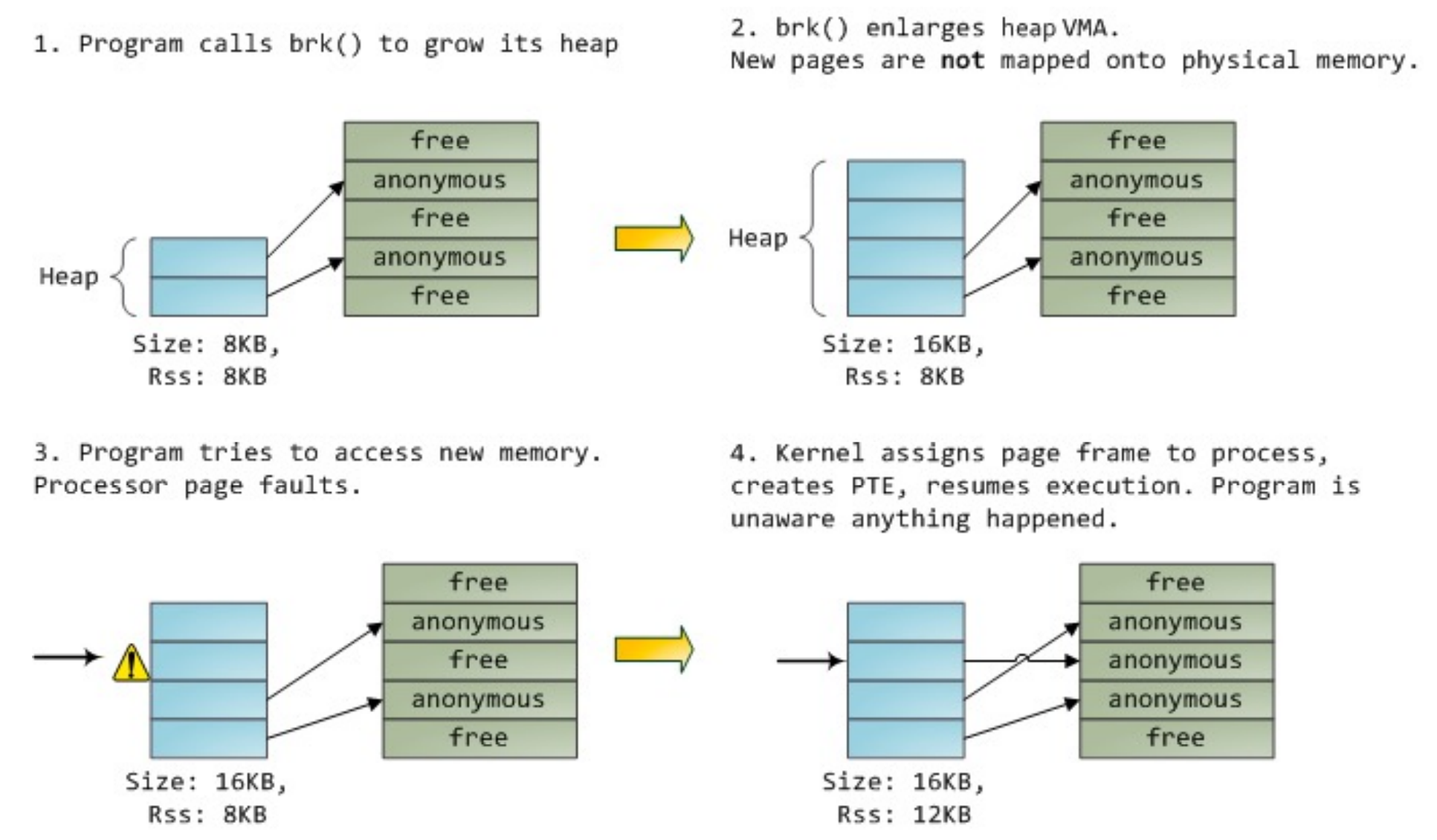
-
查的是VMA
-
Each page table entry has a valid–invalid (present) bit
- \(v\) means frame mapped, \(i\) means frame not mapped
- 一开始所有entry的这一位都被设置为\(i\)
- during address translation, if the entry is invalid, it will trigger a page fault
Who handles page fault?¶
Linux implementation
Page Fault 出现有两种情况,一种是地址本身超过了 vma 的范围,或者落在 Heap 内但权限不对,这种情况操作系统会杀死进程;一种是落在 Heap 里,而且权限也正确,那么这个时候 OS 就会分配一个空闲帧,然后把这个页映射到这个帧上。
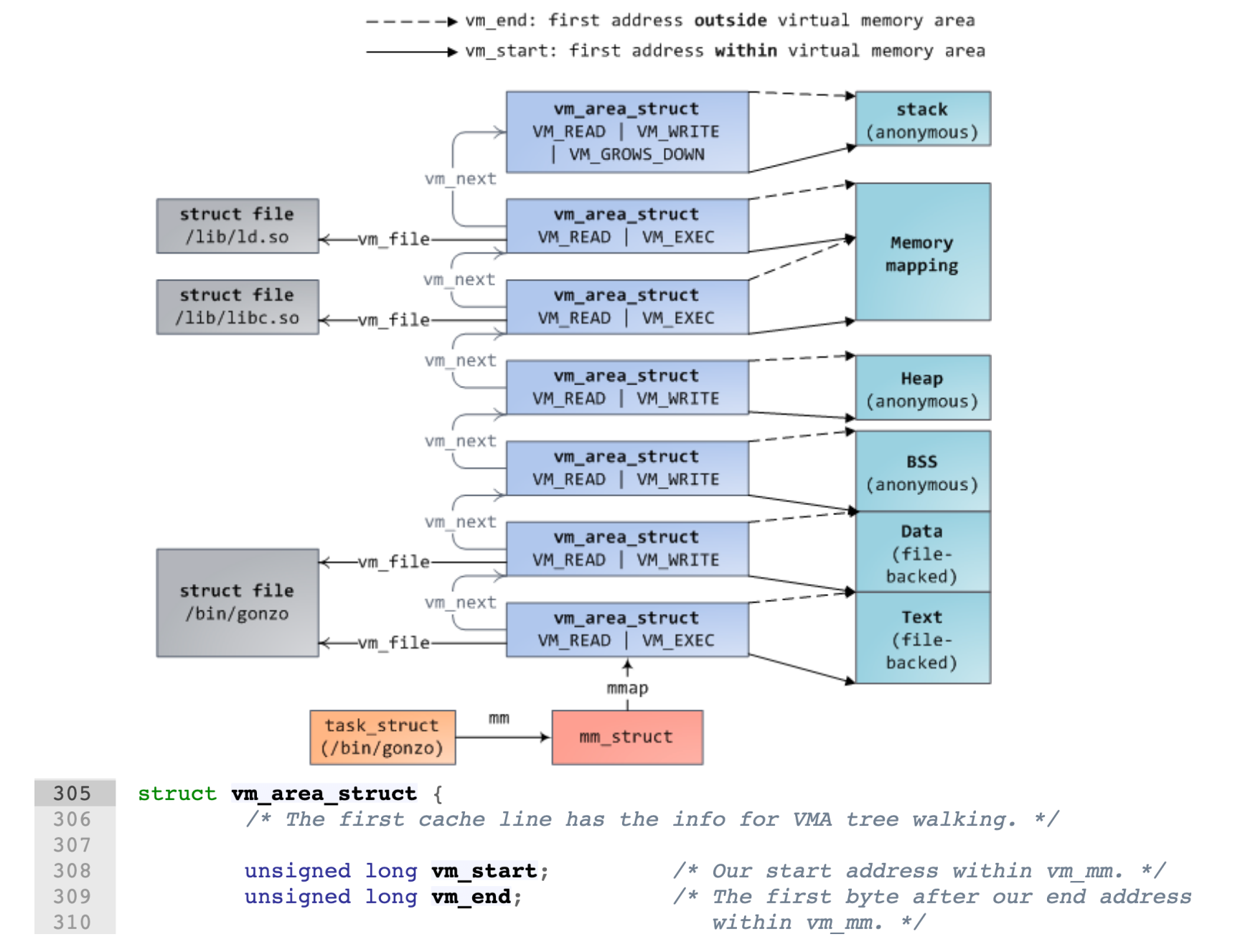
为了判断地址是否落在 vma 里,Linux 使用了红黑树来加速查找。
Page Fault Handling

Page Fault¶
- 分成major page fault和minor page fault
- major: 需要访问硬盘
-
minor: 不在虚拟地址空间,但是在物理内存
-
First reference to a non-present page will trap to kernel: page fault.
-
Operating system looks at memory mapping to decide:
-
invalid reference -> deliver an exception to the process
- Via check vma in Linux
注意这里的 valid 不是指 page table 的有效,而是访问的地址在 vma 里,而且权限正确。
-
valid but not in physical memory -> bring in
- get an empty physical frame
- bring page into frame via disk operation
- set page table entry to indicate the page is now in memory
- restart the instruction that caused the page fault
-
extreme case: 开始进程时memory内没有frame,又叫pure demand paging
-
OS sets instruction pointer to first instruction of process
- invalid page ➠ page fault
- every page is paged in on first access
- program locality reduces the overhead
- an instruction could access multiple pages ➠ multiple page
Swapper¶
- Lazy swapper: never swaps a page in memory unless it will be needed
- the swapper that deals with pages is also caller a pager
- Pre-Paging: pre-page all or some of pages a process will need, before they are referenced
- it can reduce the number of page faults during execution
- if pre-paged pages are unused, I/O and memory was wasted
- although it reduces page faults, total I/O# likely is higher
Get Free Frame¶
-
Most operating systems maintain a free-frame list -- a pool of free frames for satisfying such requests
-
Operating system typically allocate free frames using a technique known as zero-fill-on-demand -- the content of the frames zeroed-out before being allocated
为了防止信息泄露,在分配时把帧的所有位都置 0。
Stages in Demand Paging – Worse Case¶
- Trap to the operating system.
- Save the user registers and process state. (
pt_regs) - Determine that the interrupt was a page fault.
- Check that the page reference was legal and determine the location of the page on the disk.
- Issue a read from the disk to a free frame: - Wait in a queue for this device until the read request is serviced. - Wait for the device seek and/or latency time. - Begin the transfer of the page to a free frame.
- While waiting, allocate the CPU to other process. 等待读取的过程中,CPU分配给其他process
- Receive an interrupt from the disk I/O subsystem. (I/O completed) - Determine that the interrupt was from the disk. - Mark page fault process ready. 第一次mark为ready
- Handle page fault: wait for the CPU to be allocated to this process again. 等待第二次 - Save registers and process state for other process. - Context switch to page fault process. - Correct the page table and other tables to show page is now in memory.
- Return to user: restore the user registers, process state, and new page table, and then resume the interrupted instruction.

Demand Paging: EAT¶
-
page fault rate: \(0\leq p\leq1\)
-
Effective Access Time(EAT): $$ \begin{aligned} (1-p)\times\text{memory access} + p\times(\text{page fault overhead} + \text{swap page out} + \newline \text{swap page in} + \text{instruction restart overhead}) \end{aligned} $$
Example

Demand Paging Optimizations¶
-
Swap space I/O faster than file system I/O even if on the same device.
-
Swap allocated in larger chunks, less management needed than file system.
-
Copy entire process image from disk to swap space at process load time
-
Then page in and out of swap space
-
Used in older BSD Unix
-
Demand page in from program binary on disk, but discard rather than paging out when freeing frame (and reload from disk next time)
-
Following cases still need to write to swap space
- Pages not associated with a file (like stack and heap) – anonymous memory
- Pages modified in memory but not yet written back to the file system 脏数据
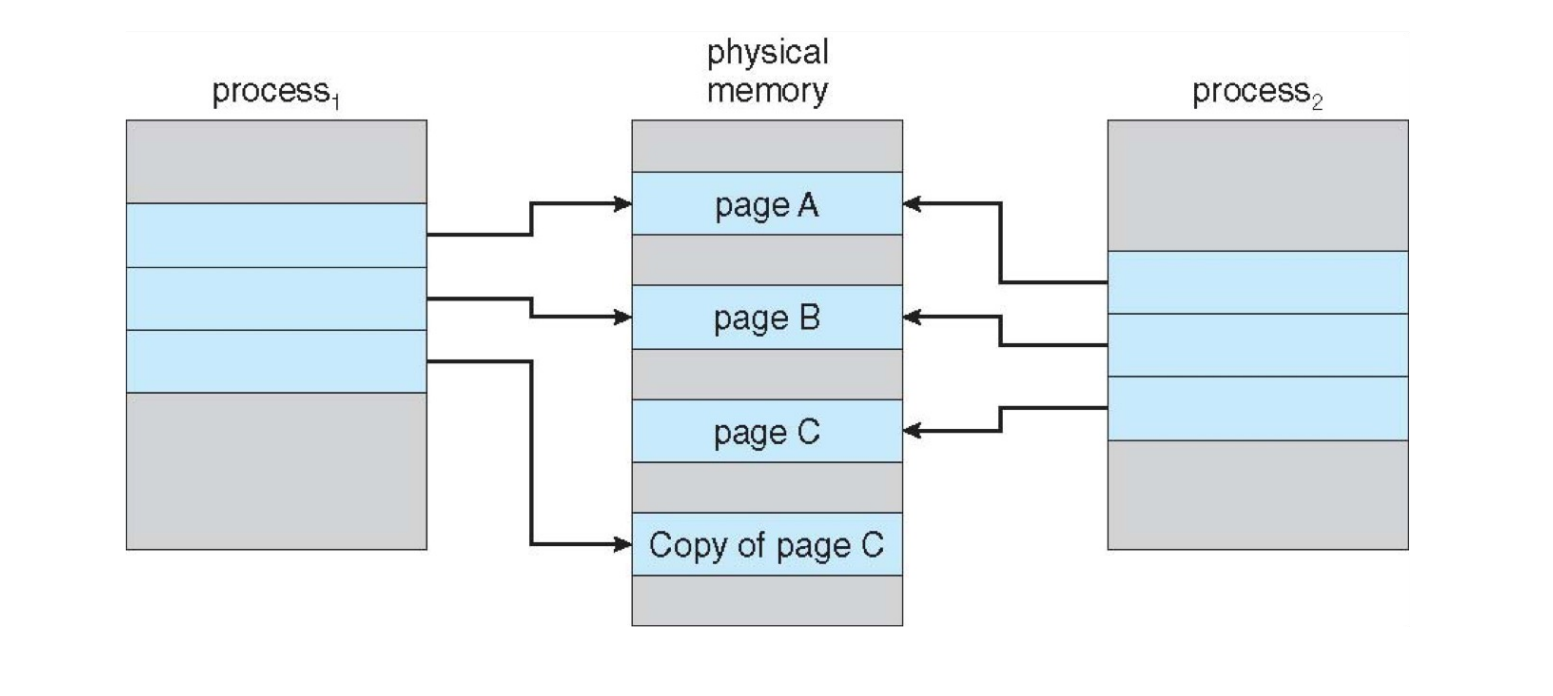
Copy-on-Write¶
- Copy-on-write (COW) allows parent and child processes to initially share the same
pages in memory
-
the page is shared as long as no process modifies it
-
if either process modifies a shared page, only then is the page copied
被写后才真正的进行copy,提升fork的效率
vfork syscall optimizes the case that child calls exec immediately after fork.
-
parent is suspend until child exits or calls exec.
-
child shares the parent resource, including the heap and the stack.
-
child cannot return from the function or call
exit, should call_exit.共享堆和栈,所以如果调用
exit就会弄乱父进程的堆和栈,因此只能调用_exit。 -
vfork could be fragile, it is invented when COW has not been implemented.
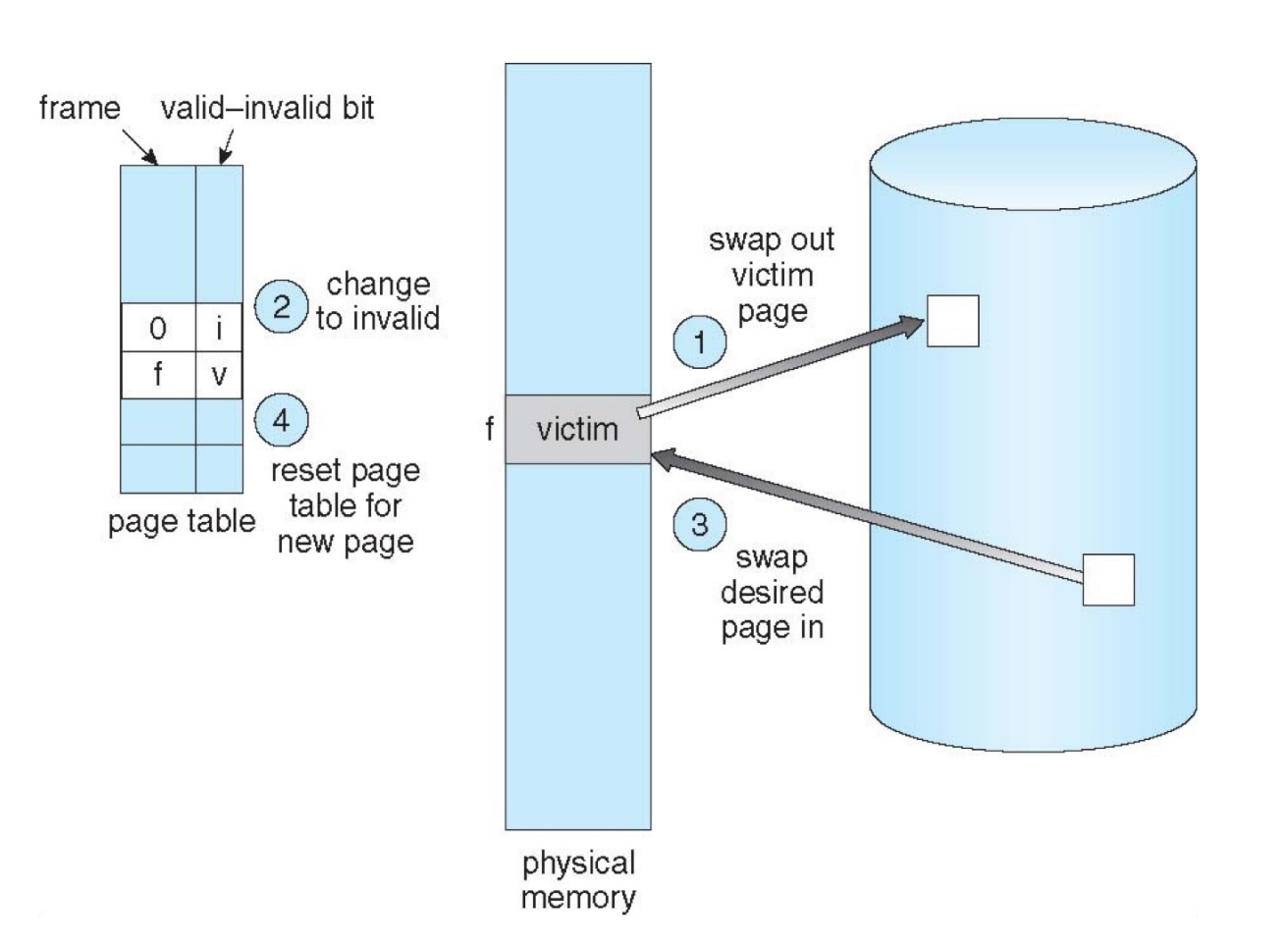
Page Replacement¶
没有空闲的物理帧时应该怎么办呢?我们可以交换出去一整个进程从而释放它的所有帧;更常见地,我们找到一个当前不在使用的帧,并释放它。
Page replacement – find some page in memory, but not really in use, page it out.
与物理地址无关
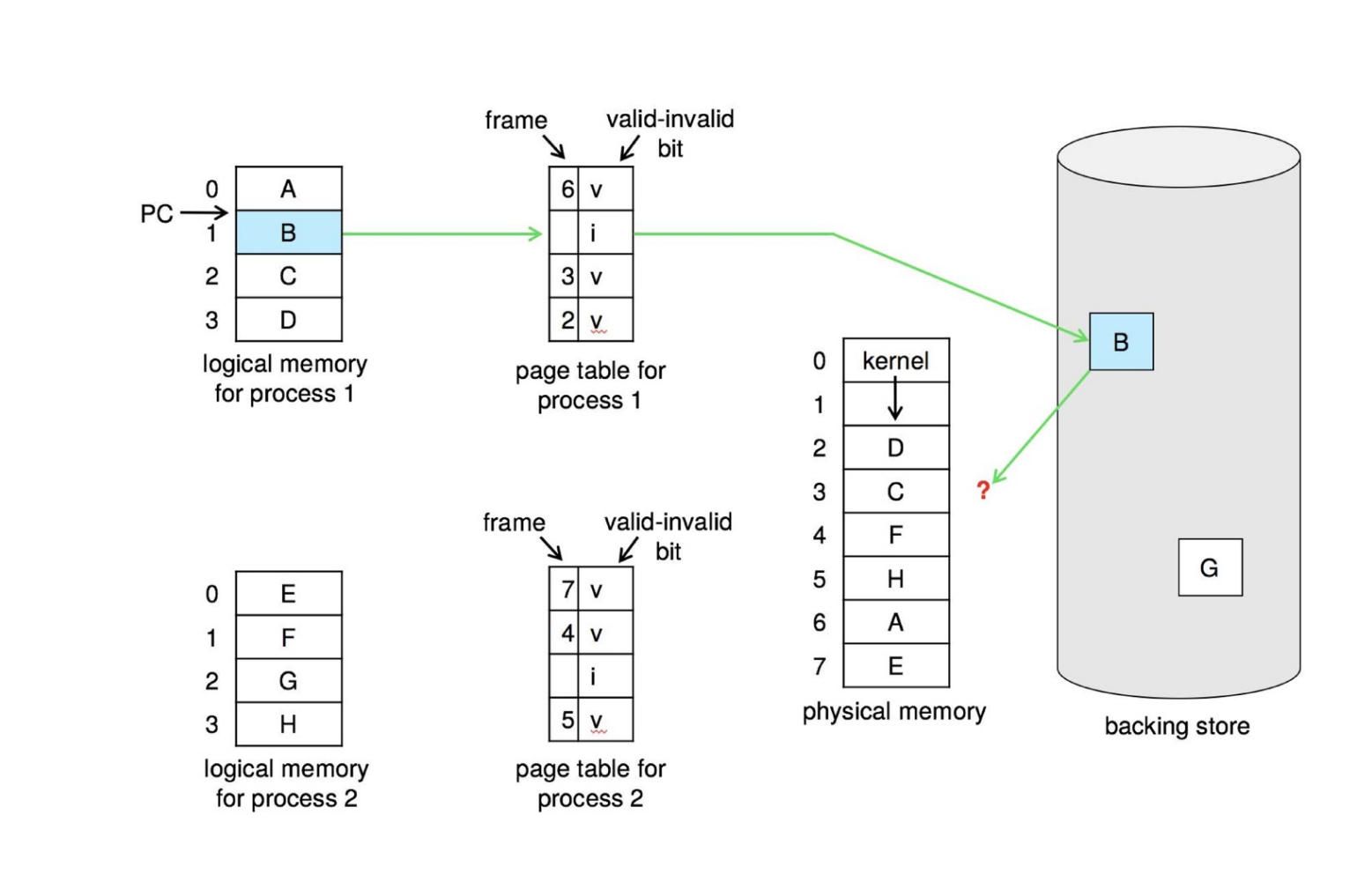
Page Fault Handler¶
-
To page in a page:
-
find the location of the desired page on disk
-
find a free frame:
- if there is a free frame, use it
- if there is none, use a page replacement policy to pick a victim frame, write victim frame to disk if dirty
-
bring the desired page into the free frame; update the page tables
- restart the instruction that caused the trap
Page Replacement Algorithms¶
- Page-replacement algorithm should have lowest page-fault rate on both first access and re-access
- FIFO, optimal, LRU, LFU, MFU…
- evaluate:用一串 memory reference string,每个数字都是一个页号,给出物理页的数量,看有多少个 page faults。
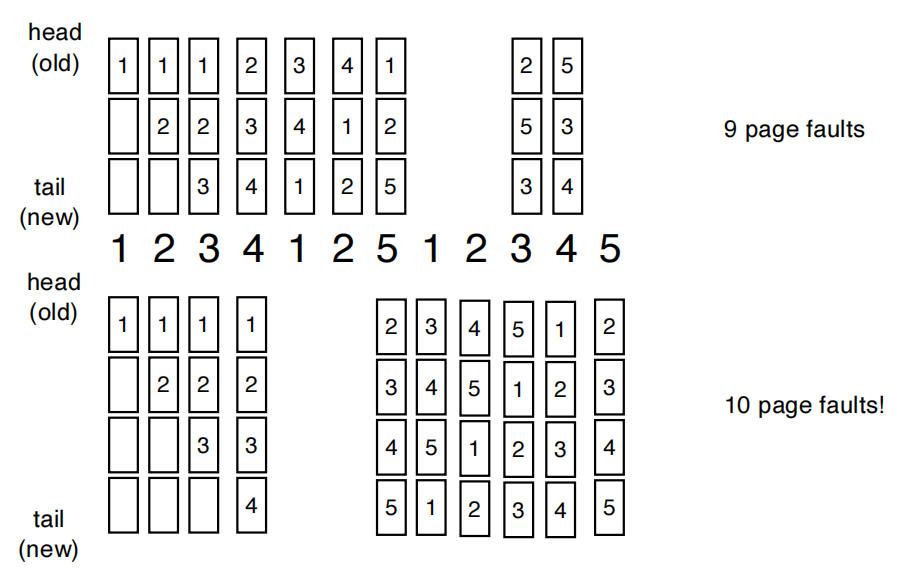
FIFO¶
- replace the first page loaded

- 以上第二个序列,3个frame只有9个page fault,但4个frame却有10个。这个问题称为Belady's Anomaly
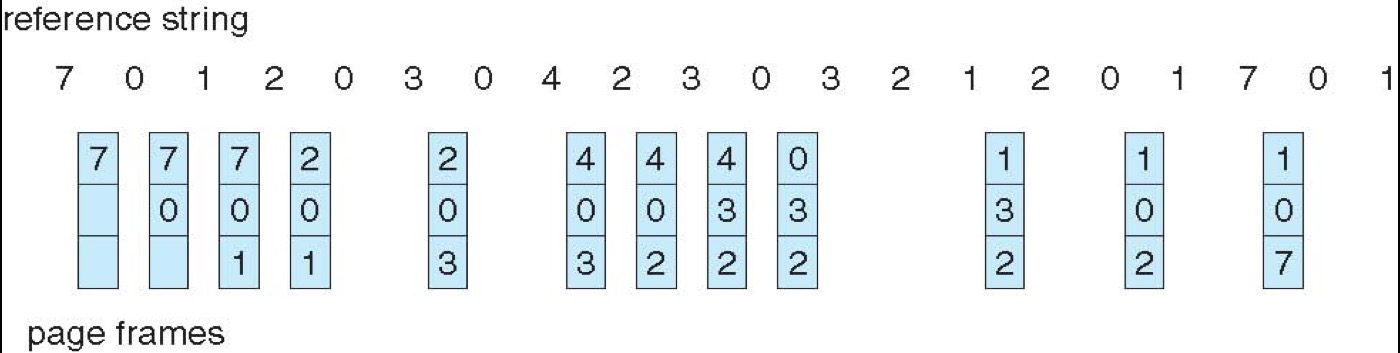
Optimal Algorithm¶
- Optimal : replace page that will not be used for the longest time
- 但实际我们完全不知道哪一页不用的时间最久,因为我们不能预测未来,用来衡量算法的性能
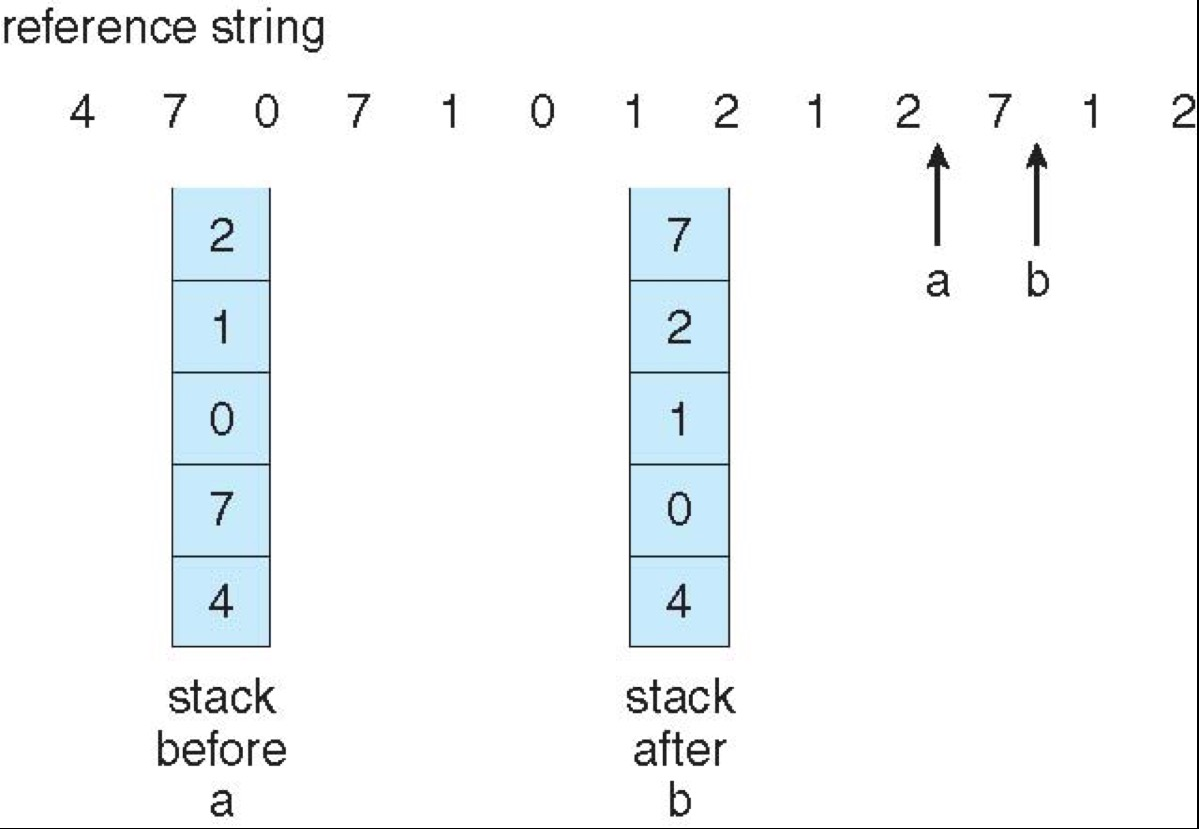
Least Recently Used(LRU)¶
-
LRU replaces pages that have not been used for the longest time
-
LRU and OPT do NOT have Belady’s Anomaly.
-
implement:
-
counter-based: 花销太大了
-
stack-based
- keep a stack of page numbers (in double linked list)
- when a page is referenced, move it to the top of the stack
- each update is more expensive, but no need to search for replacement 栈更新很耗时间
-
approximation implementation: LRU approximation with a reference bit
- associate with each page a reference bit, initially set to 0
- when page is referenced, set the bit to 1 (done by the hardware)
- replace any page with reference bit = 0 (if one exists)
-
Additional-Reference-Bits Algorithm 添加到8位
-
Suppose we have 8-bits byte for each page
-
During a time interval (100ms), shifts bit rights by 1 bit, sets the high bit if used, and then discards the low-order bits
每隔一定时间右移1位,若这次的间隔内访问了就将最高位置为1,否则置0
-
00000000 => has not been used in 8 time intervals
-
11111111 => has been used in all time intervals
-
11000100 vs 01110111 : which one is used more recently?
-
左边的,因为高位是1
-
-
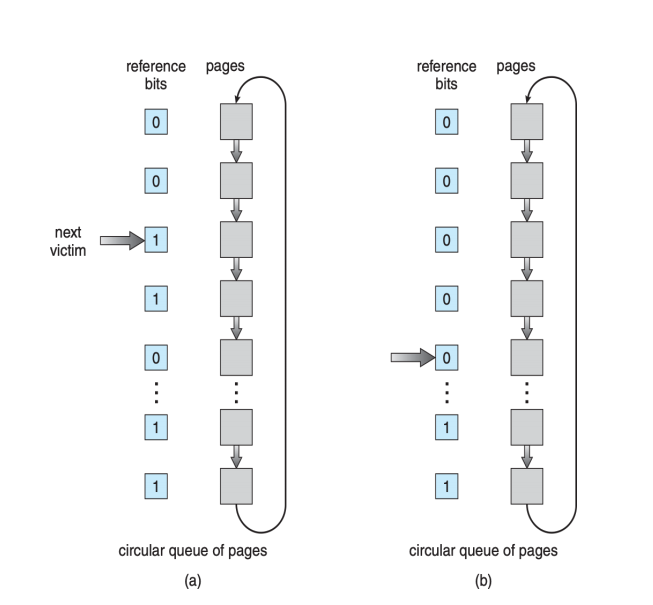
Second-chance algorithm
- Clock replacement
- If page to be replaced has
- Reference bit = 0 -> replace it
- reference bit = 1 then: 是1的就给两次机会
- set reference bit 0, leave page in memory
- replace next page, subject to same rules
-
Enhanced Second-Chance Algorithm
- Improve algorithm by using reference bit and modify bit (if available) in concert.
- Take ordered pair (reference, modify):
- (0, 0) neither recently used not modified – best page to replace.
- (0, 1) not recently used but modified – not quite as good, must write out before replacement.
- (1, 0) recently used but clean – probably will be used again soon.
- (1, 1) recently used and modified – probably will be used again soon and need to write out before replacement.
Counting-based Page Replacement¶
-
Keep the number of references made to each page
-
Least Frequently Used (LFU) replaces page with the smallest counter
-
A page is heavily used during process initialization and then never used
-
Most Frequently Used (MFU) replaces page with the largest counter
-
based on the argument that page with the smallest count was probably just brought in and has yet to be used
-
LFU and MFU are not common
Page-Buffering Algorithms¶
-
Keep a pool of free frames, always
-
frame available when needed, no need to find at fault time.
维持一个空闲帧的池子,当需要的时候直接从池子里取一个即可。
-
When convenient, evict victim.
系统不繁忙的时候,就把一些 victime frame 释放掉。(写回到磁盘,这样帧可以加到 free list 里)
-
Possibly, keep list of modified pages.
-
Possibly, keep free frame contents intact and note what is in them - a kind of cache.
-
If referenced again before reused, no need to load contents again from disk
- cache hit
Memory intensive applications can cause double buffering - a waste of memory. User 和 OS 都缓存了同一份内容,导致一个文件占用了两个帧。
Operating system can given direct access to the disk, getting out of the way of the applications
- Raw disk mode. 赋予操作系统直接访问磁盘的权限。
Allocation of Frames¶
-
Each process needs minimum number of frames -according to instructions semantics
-
type
-
Equal allocation
-
Proportional allocation
- Allocate according to the size of process
- Dynamic as degree of multiprogramming, process sizes change
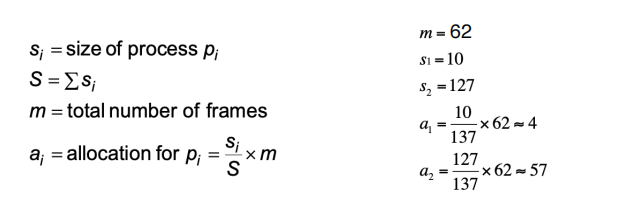
-
global vs. local allocation
-
global: process selects a replacement frame from the set of all frames; one process can take a frame from another
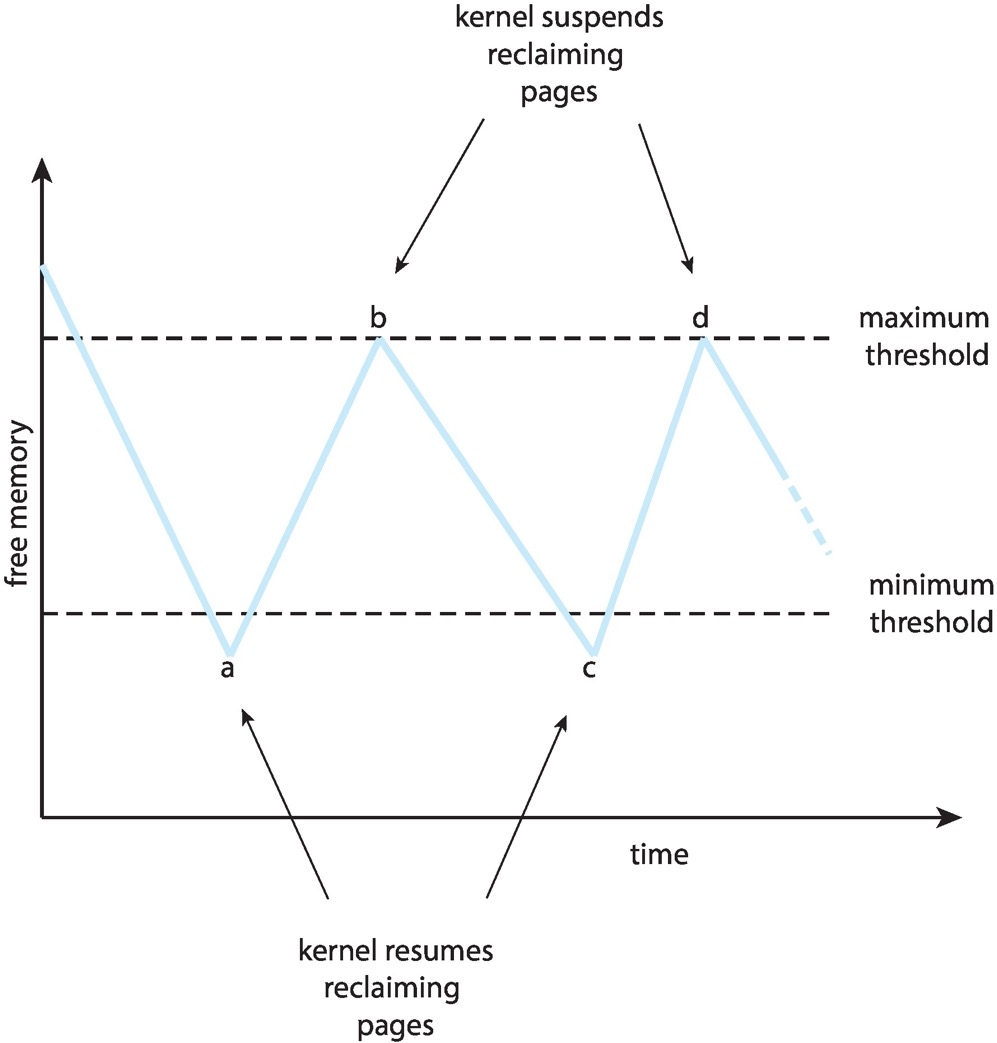
- Reclaiming Pages: page replacement is triggered when the list falls below a certain threshold.
如果 free list 里的帧数低于阈值,就触发 page replacement。这个策略希望保证这里有充足的自由内存来满足新的需求。
-
local: each process selects from only its own set of allocated frames
只能从自己的帧里选。
-
Major and minor page faults
- Major: page is referenced but not in memory
- Minor: mapping does not exist, but the page is in memory
- Shared library
- Reclaimed and not freed yet
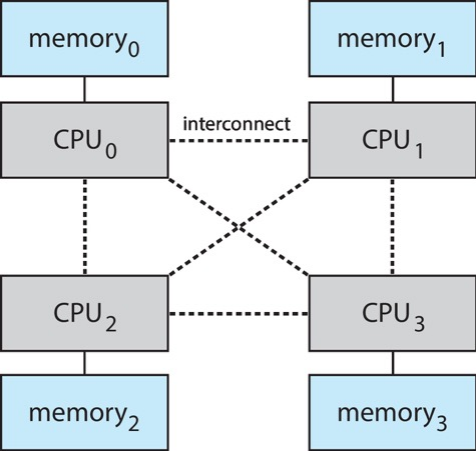
Non-Uniform Memory Access¶
不同 CPU 距离不同的内存的距离不同,因此访问时间也不同。
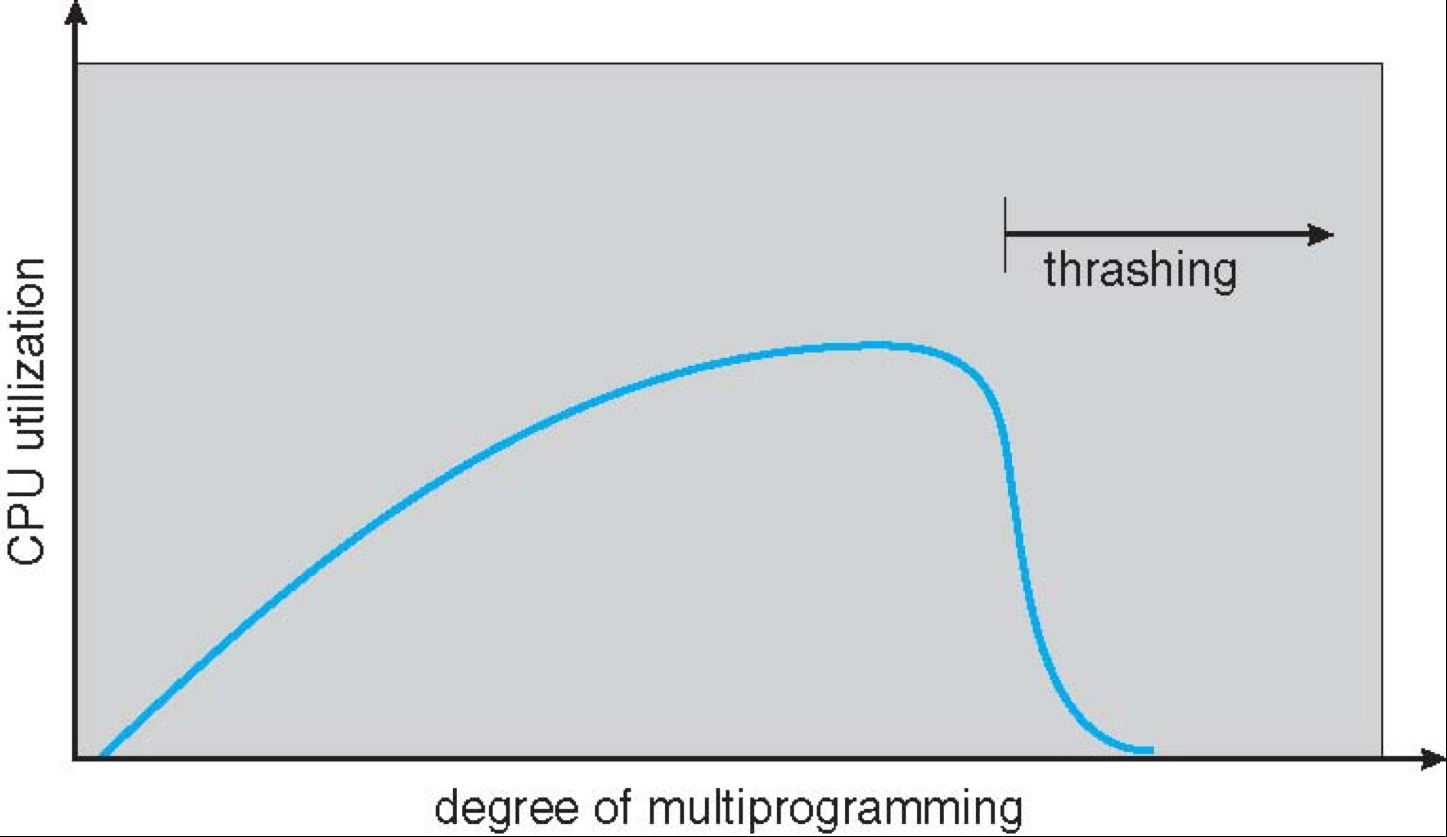
Thrashing¶
Thrashing: a process is busy swapping pages in and out.
如果我们的进程一直在换进换出页,那么 CPU 使用率反而会降低。进程越多,可能发生一个进程的页刚加载进来又被另一个进程换出去,最后大部分进程都在 sleep。
解决方法直接kill掉一些进程就好
-
Why does demand paging work?
-
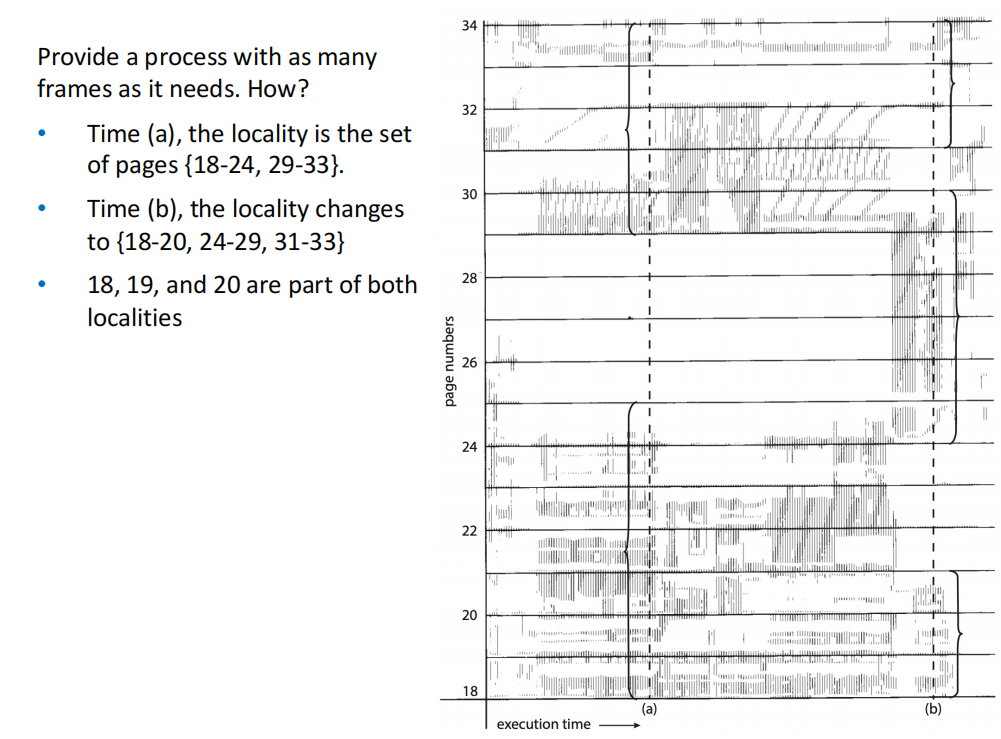
process memory access has high locality.
-
process migrates from one locality to another, localities may overlap.
-
Why does thrashing occur?
-
total memory size < total size of locality
一个 locality 大小比内存大,因此我们不得不一直换进换出页。
Resolve thrashing¶
- Limit thrashing effects by using local page replacement - One process starts thrashing does not affect others -> it cannot cause other processes thrashing - Select swap out page from the same process
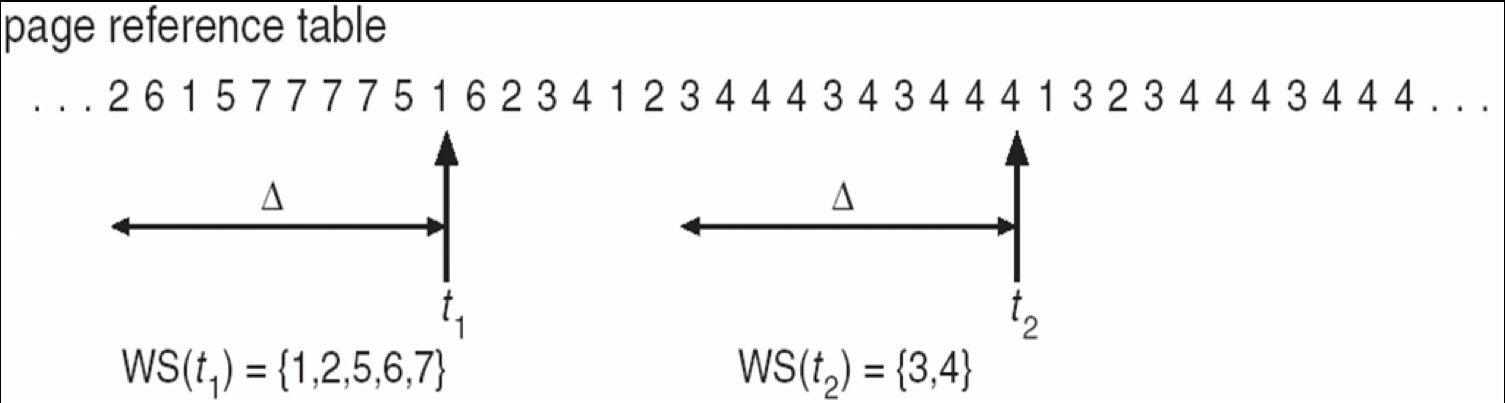
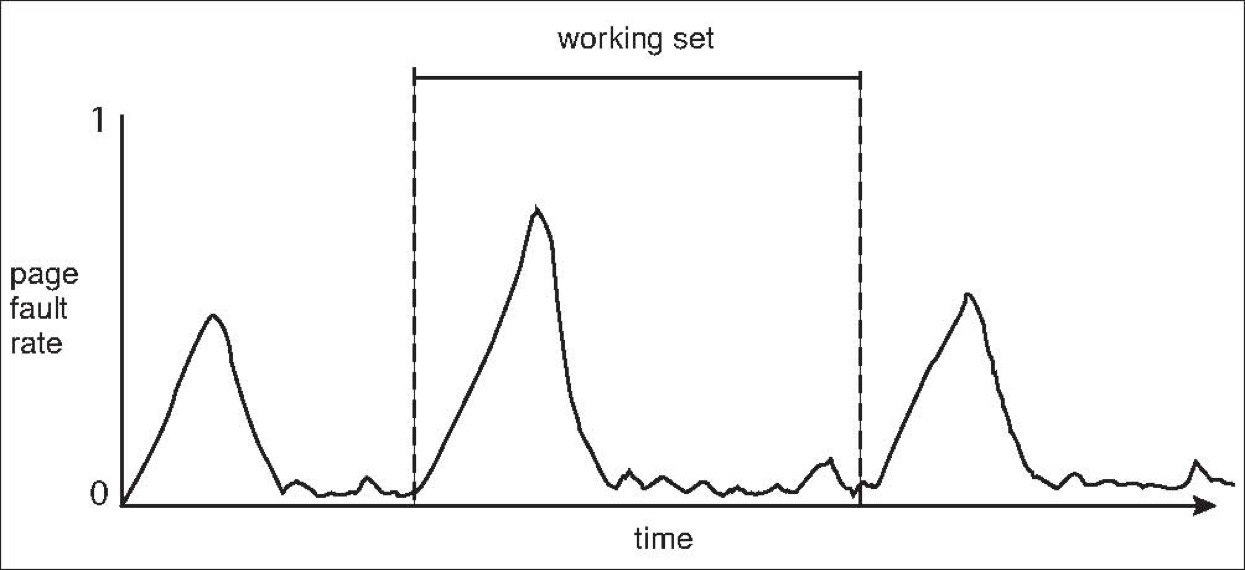
- Working-Set Model
- Working-set window(\(\Delta\)): a fixed number of page references
把所有的 locality 称为一个工作集,windows 是一个关于时间的窗口,代表最近 \(\Delta\) 次对页面的访问。
-
Working set of process \(p_i\) (WSSi): total number of pages referenced in the most recent \(\Delta\) (varies in time)
-
Total working sets: \(D = \sum\) WSSi
确定一个进程频繁访问的页面,保证这些页面不被换出;需要调页时从剩余的页面进行交换。如果频繁访问的页面数已经大于了当前进程可用的页面数,操作系统就应当把整个进程换出,以防止出现抖动现象。
- \(\Delta=10\)
怎样找到工作集? an interval timer + a reference bit,访问了这个界面就把 reference bit 置 1,当定时器到了之后,我们就可以根据 reference bit 来将这个页面放到工作集中。

Other Considerations¶
-
kmalloc: 要求虚拟地址连续,物理地址也连续 -
vmalloc: 要求虚拟地址连续,物理地址可以不连续 -
prepaging: To reduce the large number of page faults that occurs at process startup
- Prepage all or some of the pages a process will need, before they are referenced
- But if prepaged pages are unused, I/O and memory was wasted
- page size:
- Fragmentation -> small page size
- Page table size -> large page size
- Resolution -> small page size
- I/O overhead -> large page size
- Number of page faults -> large page size
- Locality -> small page size
- TLB size and effectiveness -> large page size
现在倾向于large,因为内存便宜了
- TLB reach: the amount of memory accessible from the TLB
- = TLB size x page size
- Increase the page size to reduce TLB pressure
- program structure can affect page faults (如多层for循环的顺序)

- I/O interlock: Pages that are used for copying a file from a device must be locked from being selected for eviction by a page replacement algorithm
Linux Buddy System¶
Buddy system 从物理连续的段上分配内存;每次分配内存大小是 2 的幂次方,例如请求是 11KB,则分配 16KB。
split the unit into two “buddies” until a proper sized chunk is available
当分配时,从物理段上切分出对应的大小(每次切分都是平分)。
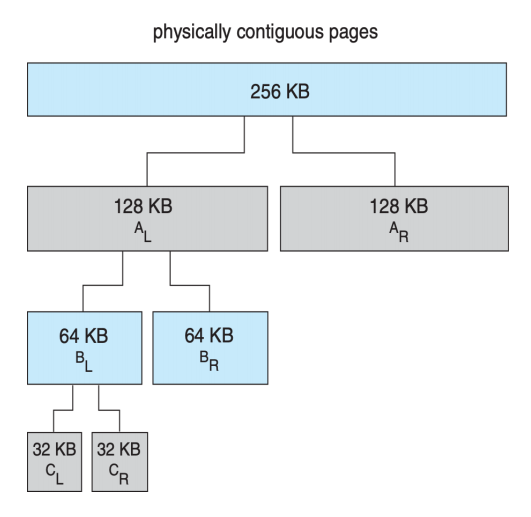
它被释放时,会合并 (coalesce) 相邻的块形成更大的块供之后使用。
- advantage: it can quickly merge unused chunks into larger chunk.
可以迅速组装成大内存(释放后即可合并)。
- disadvantage: internal fragmentation
Slab Allocation¶
要分配很多 task_struct,如何迅速分配。我们把多个连续的页面放到一起,将 objects 统一分配到这些页面上。
Slab allocator is a cache of objects.
- a cache in a slab allocator consists of one or more slabs
- a slab contains one or more pages, divided into equal-sized objects
Upon request, slab allocator
- Uses free struct in partial slab
- If none, takes one from empty slab
- If no empty slab, create new empty
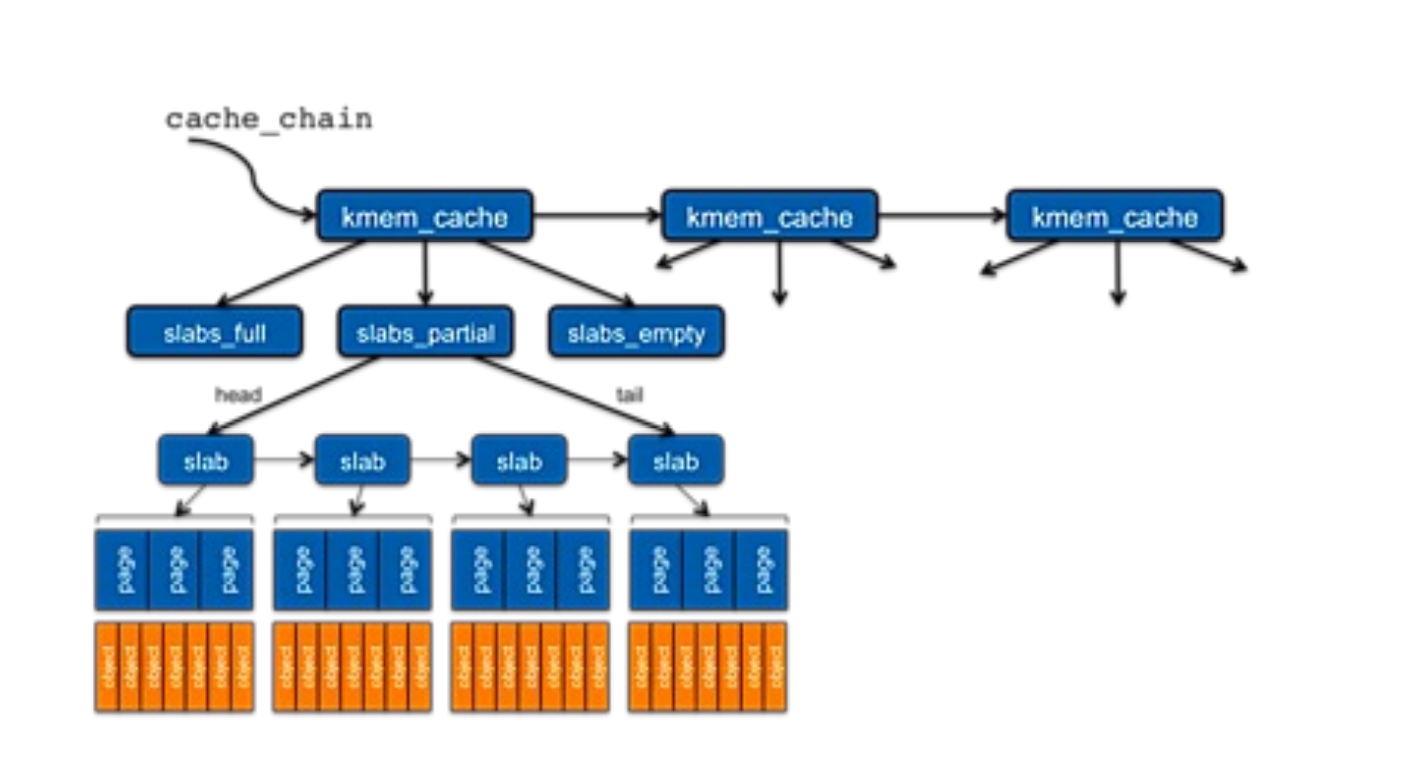
A 12k slab (3 pages) can store 4 3k objects.

- mm_struct里存的是user page table
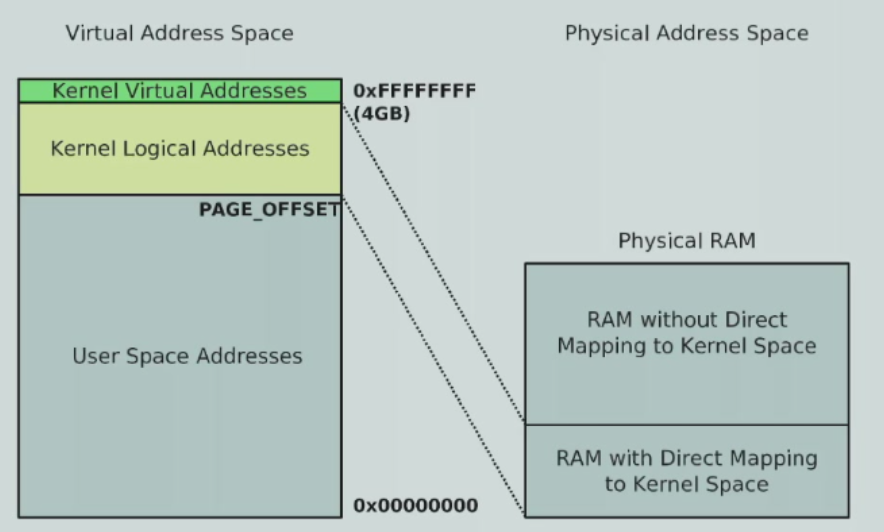
Large physical RAM¶
- how about large physical RAM >= 1GB, even larger than the kernel AS
- For large memory systems (more than ~1GBRAM), not all of the physical RAM can be linearly mapped into the kernel's address space.
- Kernel address space is the top 1GB of virtual address space, by default.
- Further, 128 MB is reserved at the top of the kernel's memory space for non-contiguous allocations
- kernel logical address部分是linear mapping的,virtual address部分是nonlinear mapping
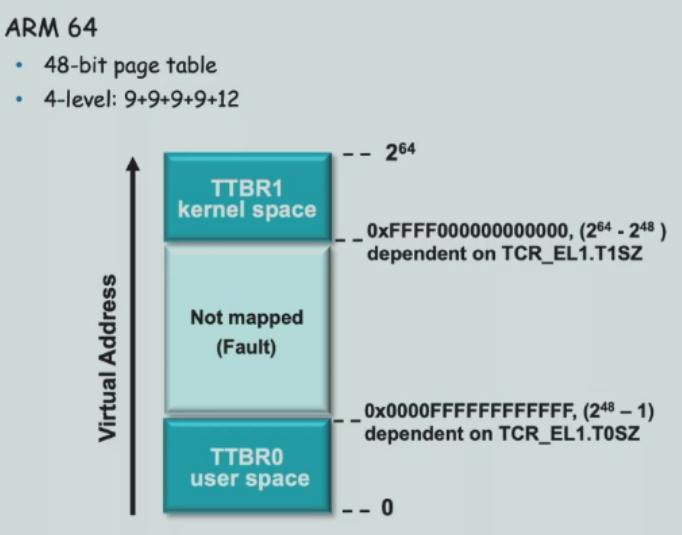
- ARM64 每次进程切换换的是TTBR0
- only the bottom part of physical RAM has a kernel logical address
- 只有低896MB可以被映射
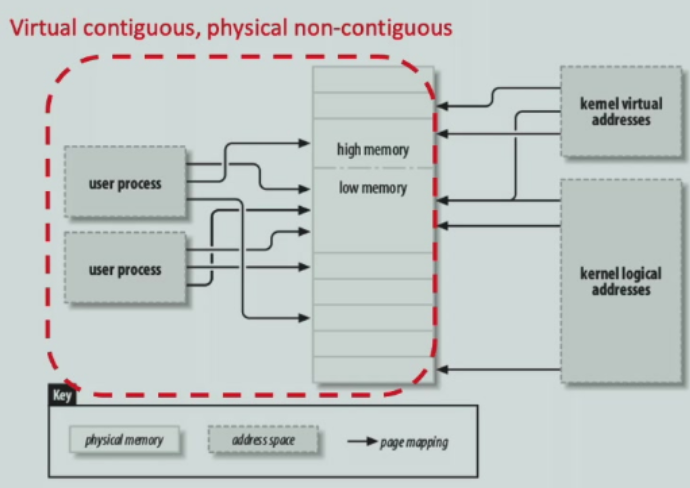
- RMAP: maps physical frames to virtual addresses