7 Practical Topics in Deep Learning¶
Batch Normalization¶
- 让每一个batch平均值0,方差1,让数值更稳定,避免梯度爆炸和梯度消失
- 会降低DNN的表达能力
-
解决办法:加入正则项
$$ \hat{x}^{(k)}=\gamma\times\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}}+\beta $$
-
在学习过程中,E和Var被认为是不变的,更新按如下公式。而\(\gamma\)和\(\beta\)视为是normal parameter,在梯度下降中更新
-
compute \(E\) and \(Var\): by approximating, adopt exponentially decaying
- \(\hat{E}\big[x^{(k)}\big]_{iter+1}=0.9\times\hat{E}\big[x^{(k)}\big]_{iter}+0.1\times\frac{1}{m}\sum_{i=1}^{m}x^{(k)}_{i}\)
- \(\hat{Var}\big[x^{(k)}\big]_{iter+1}=0.9\times\hat{Var}\big[x^{(k)}\big]_{iter}+0.1\times\frac{1}{m}\sum_{i=1}^{m}(x^{(k)}_{i}-E\big[x^{(k)}\big])^{2}\)
-
完整的流程
- 每次循环,用上面的公式更新E和Var
- Update all the learnable parameters, including \(\gamma\) and \(\beta\), and all the parameters in the convolutional layers.
- Update E and Var for the usage of the next iteration
-
BN消除了梯度爆炸和梯度消失
Data Augmentation¶
- 数据增强:作用是扩大数据集,避免过拟合,对图像而言常用操作有:裁剪放缩、镜像、saturation(饱和度)、旋转、luminosity(光照)
Neural Network Pruning¶
- universal pipeline for pruning

-
weight-level pruning:
- set unimportant weights to zeros: weights with small absolute values, have the least influence
- cut down parameters directly
- 权重矩阵变得稀疏,更好存储和压缩,forward更快
- mobile设备上稀疏矩阵的support受限
-
filter-level pruning:
- pruning unimportant filters or feature maps: filters with small \(l_p\) norm and feature maps with small mean activation values 删掉对应的filter和feature map的作用是一样的
- cut down parameters and computations directly
- 和其他filter信息相似的是不重要的
-
layer-level pruning/block-level:
- pruning redundant layers(blocks)
- cut down parameters and computations directly
- 损害特征之间区分度的block是不重要的
GAN¶
- generative model: given data \(\{x_i\}_{i\in I}\) sampled from real distribution \(p(x)\), we want to sample new data \(x \sim p(x)\)
你希望可以从这些sample点中获取背后真实的分布
-
generative adversarial network
- generator: 从固定高斯分布的噪音中sample若干个点(32/64/...)作为generator输入,经过network生成对应的图像输出
- discriminator: 一半输入是generator生成的fake图,一般是真实数据,进行linear regression。
- 目标:D最大化判别概率,G让D最小

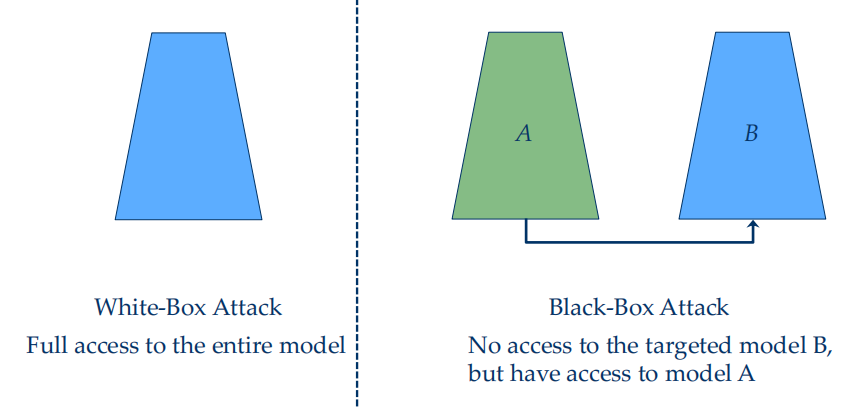
Adversarial Attacks and Defense¶
-
an intriguing property of DNN: a small shift \(v\) onto the input image can completely change the prediction of DNN on purpose 白盒
- 鲁棒性优化:在样本点周围的球体内做优化
-
Attack Algorithm:找到\(v=\Delta x\)可以增加loss value
- maximize loss l: \(v=\Delta x=\epsilon\times\dfrac{\partial l}{\partial x}\)
-
黑盒攻击:
- 要攻击的网络黑盒,通过调取原网络api或者利用公开数据集,猜测网络结构,训练另一个网络。
-
Defense Algorithm 进行对抗训练
- In each iteration of training, we first attack the model to get \(x'\) then adopt it for training
$$ x'=x+\epsilon\times\frac{\partial l}{\partial x} $$
-
Then we compute the loss value given \(x'\) rather than \(x\) $$ L'=CrossEntropy(\theta,x',y) $$
-
Then we minimize \(L'\) by compute the gradient of \(\theta\)
$$ \Delta\theta=-lr\times\frac{\partial L'}{\partial\theta} $$
- Repeat 1~3 until convergence
Attention Mechanism¶
- old Seq2Seq model: easy to forget the first part when the sequence is long
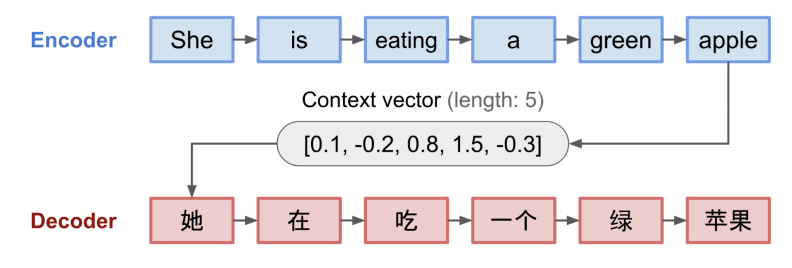
- need a mechanism to pay attention to the entire source input
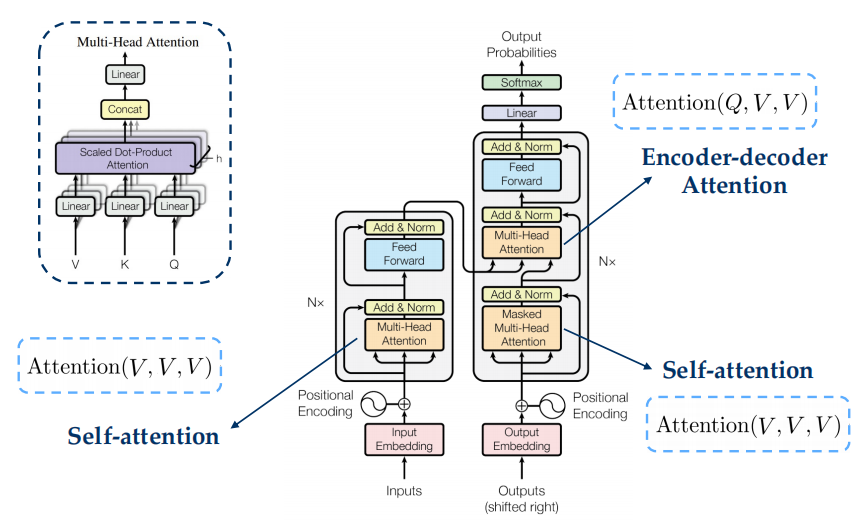
- Attention - Attention(Q,K,V)=\(\text{softmax}(\dfrac{QK^T}{\sqrt{d_k}})V\)
- Transformer
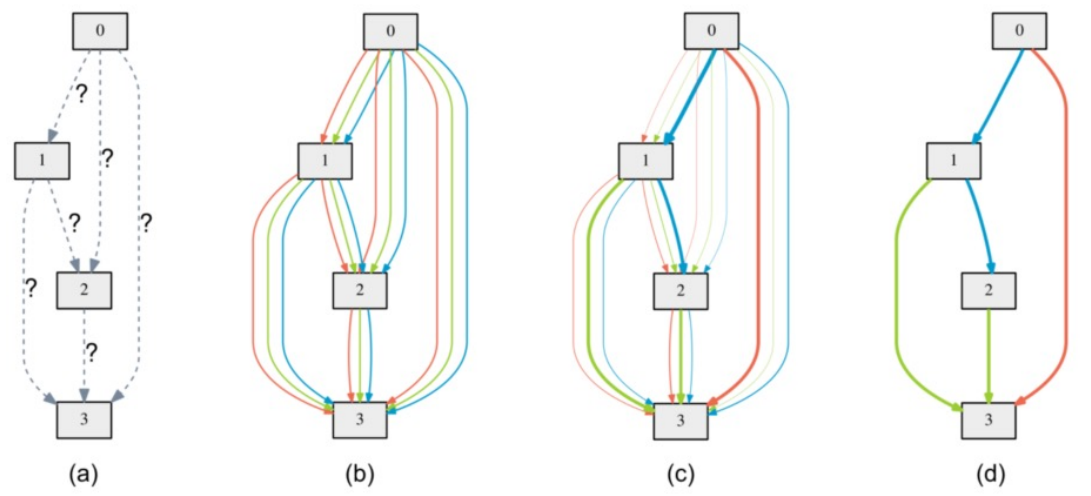
Neural Network Architecture Search(NAS)¶
- In NAS, a neural network is seen as an directed acyclic graph (densely connected). Edges represent operations (e.g., conv, relu, etc.), and nodes represent input and output. What we do is determining the best operation between each two node
- The real output of a layer is the weighted sum of all candidate operations, where weights are trainable parameters.
- Edges with largest weights are kept while others are deleted.