7 Neural Networks¶
Deep Learning¶
-
Linear model
\[ f(x)=w^Tx+b=0 \ \ \ \text{Hyperplane} \newline r=\frac{f(x)}{\|w\|}\ \ \ \text{distance} \] -
Perceptron
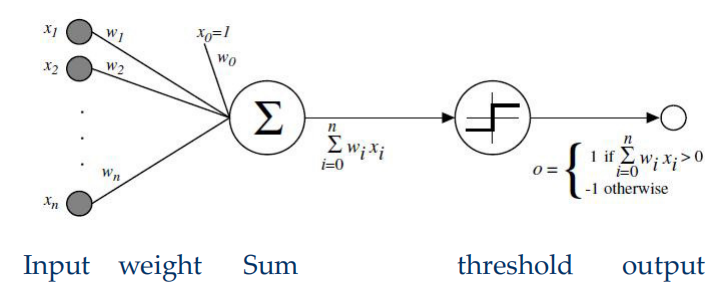
-
单层: 预测某个x错误,则\(w_t=w_{t-1}+xy\)
-
多层
- If an example can be correctly predicted, No penalty.
\[ \begin{aligned} J(w)&=-\sum_{i\in I_M}w^Tx_iy_i \newline \nabla J&=\sum_{i\in I_M}-x_iy_i \newline \text{gradient descent}\quad &w(k+1)=w(k)+\eta(k)\sum_{i\in I^k_M}x_iy_i \end{aligned} \]batch learning:所有sample都available
-
online learning/mini-batch learning: 学习算法只能one by one的看训练数据
- 训练速度快,memory消耗小
- 具有实时性,可以快速适应新数据的特征变化
- 需要进行一定的模型设计和优化,以提高算法的效率和准确性
-
mistake bound theorem

-
-
Bias-variance Decomposition

-
Any continuous function from input to output can be implemented in a three-layer net, given sufficient number of hidden units \(n_H\), proper nonlinearities, and weights.
-
对激活函数要求:非线性,有上下界,本身和导数连续且smooth
对参数:以0为中心,奇函数lead to faster learning
-
Dropout:每次训练,每个结点都按一定概率可能被激活,防止过拟合。测试时,所有node都被激活
-
CNN: 卷积、池化;越接近输出的层可以表示越复杂的特征,因为他们感受野更大
- Totally, big stride makes us harvest a big receptive field faster, but it also discards some information.
-
ResNet: 由多个residual block组成,每个block输出output=\(ReLU(x)+x\)
-
Language Modeling: 给出一系列词,计算下个word分布的概率
$$ P(x^{(t+1)}|x^{(t)},\dots,x^{(1)}) $$
-
RNN
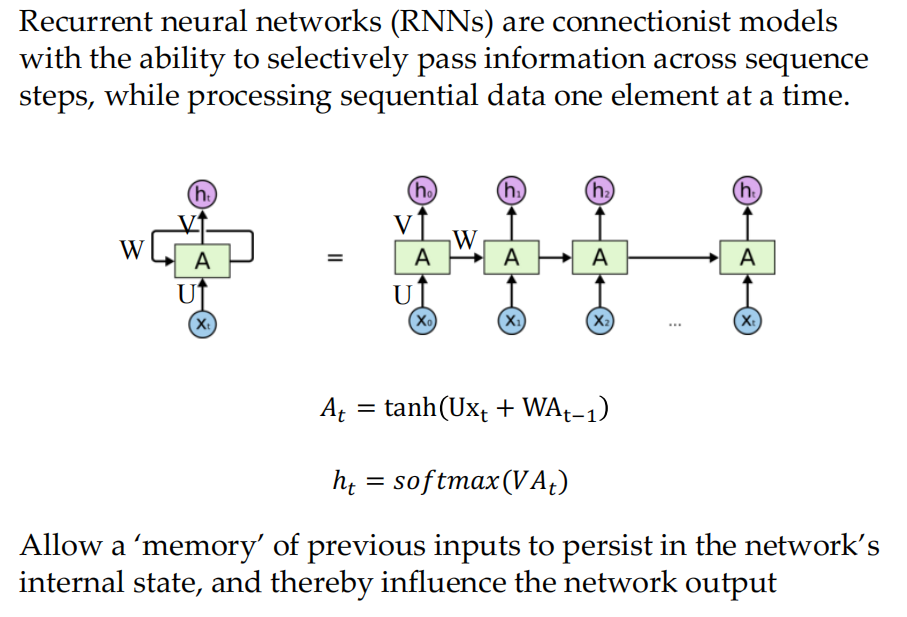
-
softmax把向量转化成概率(归一化)
-
模型大小不会随input长度增加而增加,由于每一个timestep所用的权重是一样的,因此对输入顺序是symmetry的
- 缺点在于计算recurrent process很慢,同时由于梯度消失问题,在实际中我们很难获得很多个时间步之前的信息
-
-
Vanishing Gradient Problem: Gradient contributions from “far away” steps become zero, and the state at those steps doesn’t contribute to what you are learning 获得不了很远的信息
- 对权重矩阵进行好的初始化会降低梯度消失的影响
- 使用ReLU 这样梯度更可能存下来
- 使用LSTM或GRU,现在直接LLaMa?
-
LSTM: If the forget gate is set to 1 for a cell dimension and the input gate set to 0, then the information of that cell is preserved indefinitely.
LSTM doesn’t guarantee that there is no vanishing/exploding gradient, but it does provide an easier way for the model to learn long-distance dependencies
