3 Introduction to Deep Learning¶
神经网络相关概念¶
-
激活函数:阶跃函数, sigmoid, tanh, softmax, 恒等函数, ReLU
- LeakyReLU:
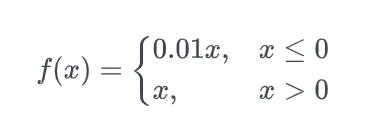
- GELU:
$$ f(x)=x\Phi(x)=\dfrac{1}{2}x(1+erf(\dfrac{x}{\sqrt2})) \ erf(x)=\dfrac{2}{\sqrt\pi}\int_0^xe^{-y^2}dy $$
-
损失函数
- 二分类常用:二分类交叉熵 \(f\)为神经网络输出,\(y\)为真实标签或回归值
$$ loss=-\dfrac{1}{N}\sum_{i=1}^Ny\ln f+(1-y)\ln(1-f) $$
- 多分类常用:分类交叉熵 \(M\)类,使用one-hot编码
$$ loss=-\dfrac{1}{N}\sum^N_{i=1}\sum_{c=1}^My_{ic}\ln(f_{ic}) $$
-
优化器 SGD和Adam比较多
- 梯度下降法
- 随机梯度下降法:每次使用数据中的一个样本的梯度作为更新梯度,开销低
- 批量梯度下降法:每次使用数据中的一个批(batch)的梯度作为更新梯度
-
引入动量的梯度计算方法

-
学习率自适应的优化算法
- AdaGrad

- RMSProp

- Adam

-
评估
- 泛化误差:在真实分布上的误差 测试误差:测试集上的误差,用于近似泛化误差
-
泛化误差的偏差-方差分解:
- 方差:训练集数据扰动的影响
- 噪音:期望泛化误差的下界,即问题本身的难度
\[ E(f;D)=bias^2(x)+var(x)+\epsilon^2 \]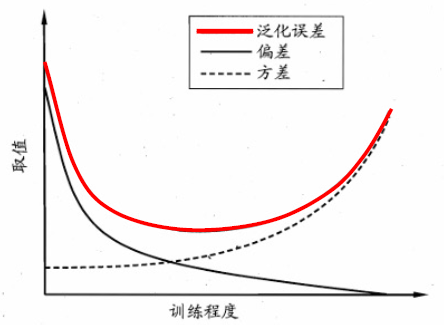
-
解决过拟合
- 早停法:在数据集中额外划分出一部分作为验证集,若训练集误差降低而验证集误差升高,则停止训练
- 正则化:通过引入噪声或限制模型的复杂度,降低模型对输入或者参数的敏感性,避免过拟合,提高模型的泛化能力。
-
Robert Hecht-Nielsen,1987,证明三层以上神经网络可以无限逼近任意连续函数
深度学习网络架构¶
CNN,RNN,LSTM,GRU 不过多介绍,已经有所了解
大模型和表示收敛¶
Transformer——以翻译为例¶
Transformer is all you need
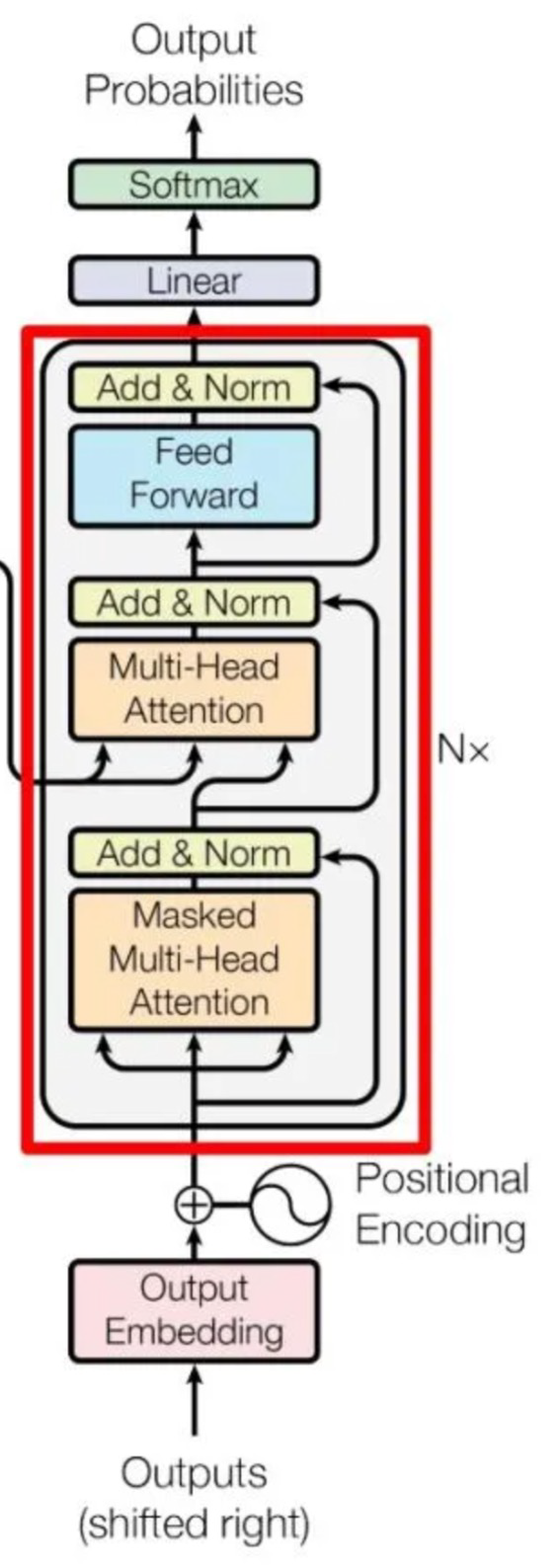
-
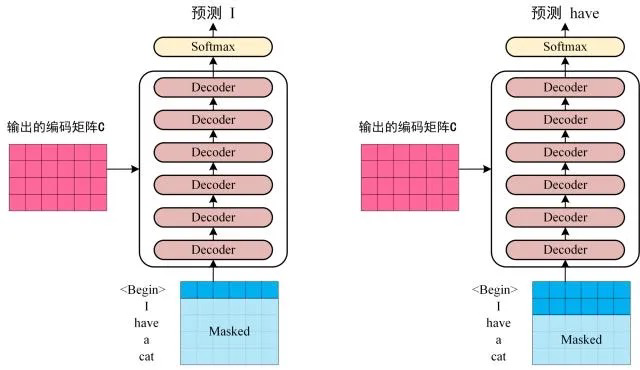
Decoder
-
包含两个Multi-Head Attention,第一个采用Masked操作,第二个的K,V矩阵使用Encoder的编码信息矩阵C进行计算,而Q使用上一个Decoder block的输出计算
-
第一层将输入矩阵和Mask矩阵相乘
-
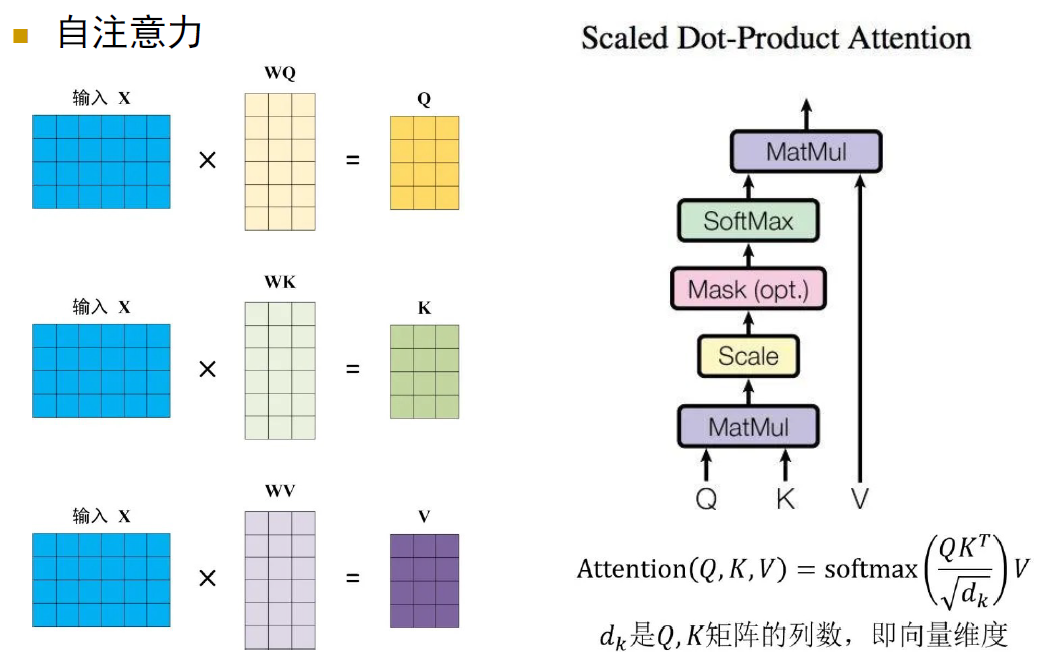
每一个词源要进行三次线性变换,分别对应Query, Key, Value,得到Q,K,V矩阵,计算\(QK^T\)
-
最后得到\(QK^T\)进行Softmax,计算attention score,之后使用\(Mask\ QK^T\)与矩阵\(V\)相乘,得到输出\(Z\)
-
通过上述步骤就可以得到一个Mask Self-Attention的输出矩阵\(Z_i\);然后和Encoder类似,通过Multi-Head Attention拼接多个输出\(Z_i\),然后计算得到第一个Multi-Head Attention的输出\(Z\),\(Z\)与输入\(X\)维度一样。
-
第二个多头注意力层,根据Encoder的输出C计算得到K,V,根据上一个Decoder block的输出Z计算Q,其余与第一层一致
-
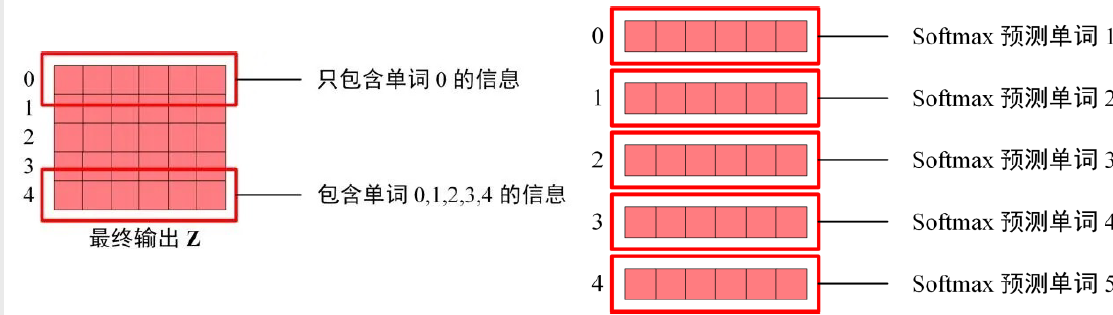
Softmax预测输出单词
- 因为Mask存在,单词0的输出\(Z_0\)只包含单词0的信息
- Softmax根据输出矩阵的每一行预测下一个单词
-
-
小结
-
并行训练
- 在输入添加位置Embedding以利用单词顺序
- 自注意力机制
表示收敛¶
核心观点:不同大模型的表示趋于收敛
“模型行为不是由架构、参数或优化器决定的。它由你的语料集决定,没有其他决定因素。其他一切因素都不过是为了有效计算以近似该语料集的手段。”