Lec.12: Computational Photography¶
High Dynamic Range Imaging(HDR)¶
-
Exposure = Gain x Irradiance x Time
- Gain is controlled by the ISO
- 越高越灵敏,也会放大噪声
- Irradiance is controlled by the aperture 光圈 f数
- Time is controlled by the shutter speed
- 按下快门,先清空之前的内容,再开始拍。这个时间差叫快门延迟。单反相机是光学取景器,传感器不需要接受光线,因此拍照时不用清空之前的内容,快门延迟比较低
- When taking a photo, the averaged exposure should be at the middle of the sensor’s measurement range. So that the photo has both bright and dark parts with details
- Gain is controlled by the ISO
-
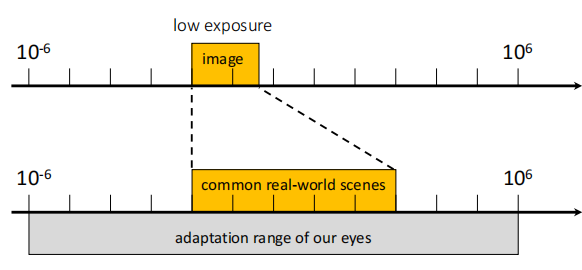
Dynamic range(动态范围): The ratio between the largest and smallest values of a certain quantity
-
Images have an even lower dynamic range because of quantization (8-bit = 256)
-
-
Key idea:
- Exposure bracketing: Capture multiple LDR images at different exposures
- Merging: Combine them into a single HDR image
-
Image formation model: Suppose scene radiance for image pixel \((x,y)\) is \(L(x,y)\). For image I, \(I(x,y)=clip[t_i\cdot L(x,y)+noise]\)
-
Merging images: For each pixel:
- Find “valid” pixels in each image
- Weight valid pixel values appropriately
- Form a new pixel value as the weighted average of valid pixel values
-
Display the HDR image: 虽然说merge后的图片动态范围很大,但是显示屏等设备可以显示的依然只有8-bit,这样想表示出很好的亮部细节和暗部细节,就会使得整个图片偏暗,为了解决这个问题,我们就需要Tone Mapping来建立一个HDR到LDR的转换公式
-
Tone Mapping
- 线性 \(X\rightarrow\alpha X\)
- 非线性(gamma compression) \(X\rightarrow\alpha X^\gamma\) \(\gamma\)大于1更暗,小于1更亮。这一方法集成在不同的相机里了,也可以后期调,但是要存成log
Deblurring¶
-
reason
- Defocus: the subject is not in the depth of view 没对上焦
- Motion blur: moving subjects or unstable camera
-
Get a clear image
- Accurate focus
- Fast shutter speed
- Large aperture
- High ISO
- One of the reasons why SLR cameras and lenses are expensive
- 使用hardware:如三脚架、云台、自带防抖
-
Modeling image blur: The blurring process can be described by convolution, the blurred image is called convolution kernel
- The blur pattern of defocusing depends on the aperture shape
- The blur pattern of shaking depends on the camera trajectory
- blurred image = clear image 与 blur kernel 做卷积
-
deblurring = deconvolution
-
Non-blind image deconvolution(NBID): \(G=F\otimes H\)
-
G: The captured image (known), F: Image to be solved (unknown), H: Convolution kernel (known)
-
快速傅里叶变换 \(F=IFFT\left(FFT(G)\div FFT(H)\right)\)
-
Usually called inverse filter Inverse filter
-
问题:大部分模糊核都是低频滤波器,做逆卷积可能会放大高频部分,从而噪音被放大了 $$ \begin{aligned} & G(u,v)=H(u,v)F(u,v)+N(u,v) \newline & \hat{F}(u,v)=G(u,v)/H(u,v)=F(u,v)+N(u,v)/H(u,v) \end{aligned} $$
-
解决方法:改变滤波器表达方式,不放大高频
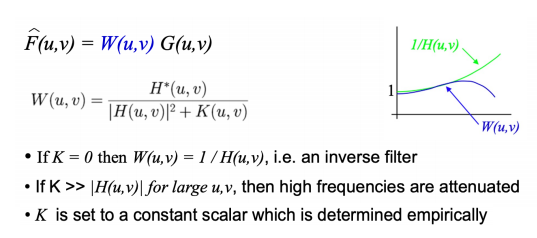
- 应用:高速看车牌(车的轨道相对固定),哈勃太空望远镜
-
-
Deconvolution by optimization 去噪音
-
要优化的变量:清晰的原图像
-
目标函数:
-
要求解的图像和用卷积核计算后模糊的图像尽可能接近 likelihood
-
复原图像尽可能real prior
-
假设噪声是高斯分布
\[ MSE=\|G-F\otimes H\|_2^2=\sum_{ij}(G_{ij}-[F\otimes H]_{ij})^2 \]-
Prior of natural image
-
Natural images are generally smooth in segments 大多数地方是光滑的
- Gradient map is sparse
- Adding L1 regularization makes the image gradient sparse 用正则项让梯度更稀疏,在原先误差加一个\(\|\nabla F\|_1\)
-
-
Blind image deconvolution(BID)
-
blur kernel是非负且稀疏的
-
优化目标函数 $$ \min_{F,H}|G-F\otimes H|_2^2+\lambda_1|\nabla F|_1+\lambda_2|H|_1 s.t. H\geq0 $$
-
-
Colorization¶
不考
黑白转彩色
add color to a monochrome picture or video with the aid of a computer
-
There are two main ways to color grayscale images:
-
Sample-based colorization: use sample image
-
Interactive colorization: paint brush interactively
Sample-based colorization¶
- Scan the target image, for each pixel:
- Find the best matching point in the sample (e.g., considering the brightness and the standard deviation with neighboring pixels)
- Assign the color of the matching point to the pixel
Interactive colorization¶

转化为优化问题 $$ J(U)=\sum_r\left(U(\text{r})-\sum_{s\in N(\text{r})}w_{rs}U\left(s\right)\right)^2 $$
- \(U(r),U(s)\): RGB values of pixel \(r,s\)
- \(N(r)\): neighborhood pixels of pixel \(r\)
- \(w_{rs}\): weight that measures similarity between \(r\) and \(s\)
- Constriant: User-specified colors of brushed pixels keep unchanged
Video colorization¶
把视频当成三维数组,同样使用优化算法
Modern approach¶
神经网络
-
Loss function for image synthesis $$ L(\Theta)=||F(X;\Theta)-Y||^2 $$
- Problem with reconstruction loss
- Cannot handle the case with multiple solutions
- Cannot measure if an image is realistic
- Problem with reconstruction loss
-
GAN
-
G tries to synthesize fake images that fool D: $$ \arg\min_G\mathbb{E}_{x,y}[\log D(G(x))+\log(1-D(y))] $$
-
G tries to synthesize fake images that fool the best D: $$ \arg\min_G\max_D\mathbb{E}_{x,y}[\log D(G(x))+\log(1-D(y))] $$
-
D can be viewed as a loss function to train G
- Called adversarial loss
- Learned instead of being hand-designed
- Can be applied to any image synthesis tasks
-
More Image Synthesis Tasks¶
-
Super-Resolution: Super Resolution using GAN
-
Image to Image Translation
- Style transfer
- Text-to-Photo
- Image dehazings
-
Pose and garment transfer
- Method
- Use parametric mesh (SMPL) to represent body pose and shape
- Use high-dimensional UV texture map to encode appearance
- Transfer the pose and appearance
-
Head Re-enactment
-
AIGC
-
Diffusion Models
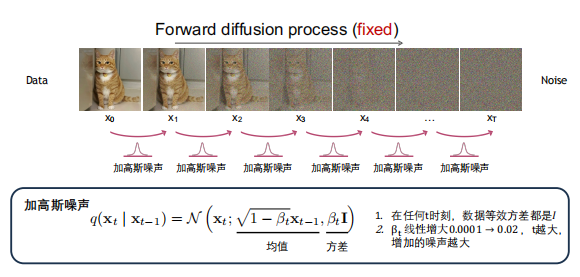
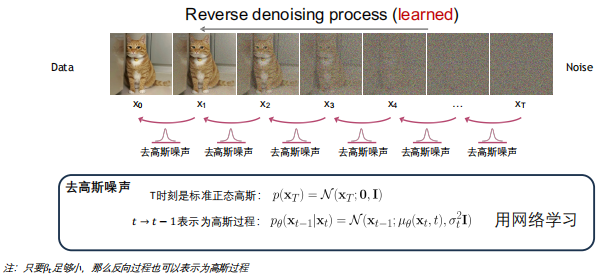
- Conditional DMs: Text-to-Image, Latent Diffusion, Text-to-Video (SORA)