Lec.10: Recognition¶
Semantic Segmentation¶

-
sliding window: 效率低,作用有限,感受野小
-
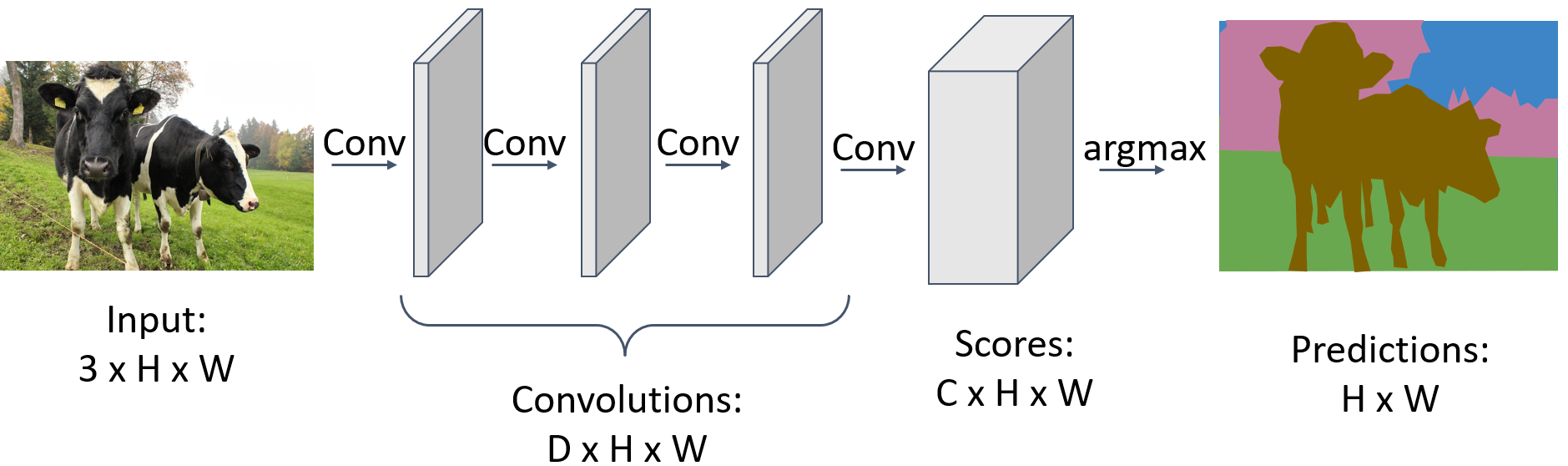
一般使用全连接神经网络
- loss function: per-pixel cross-entropy
- But convolution on high resolution is expensive
-
提高效率:使用unet
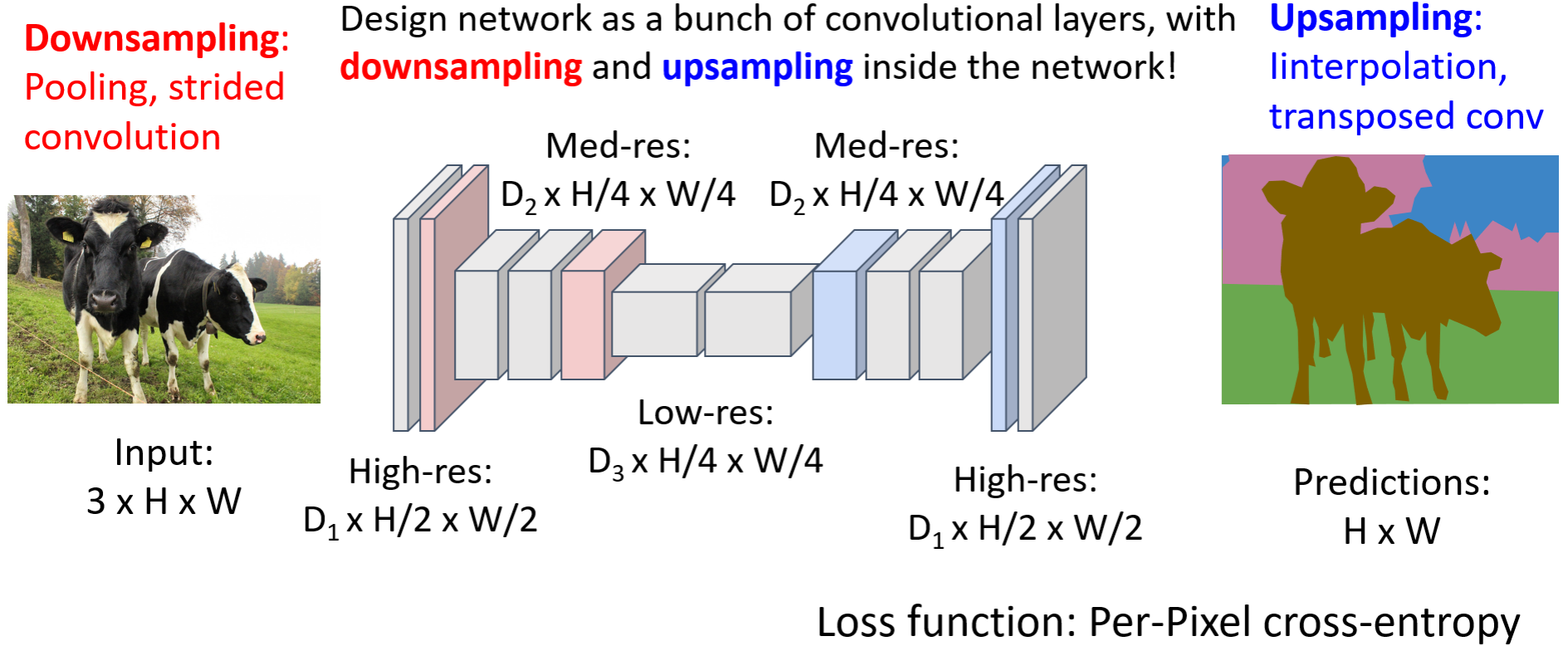
-
升维使用unpooling:可以使用bed of nails(新增的位置直接取0),nearest neighbor(和最近的一致),双线性插值,双三次插值
-
skip connection:在upsampling中直接使用downsampling过程相同大小的feature map
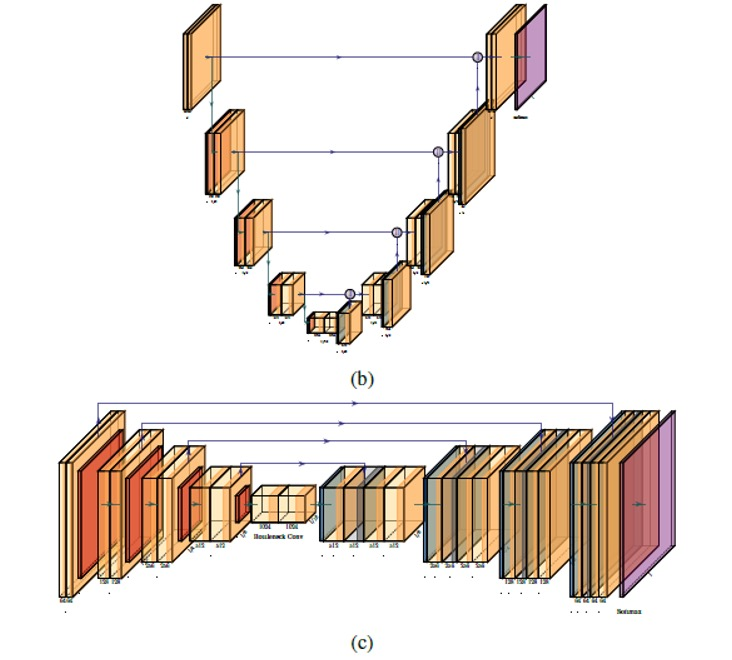
-
- loss function: per-pixel cross-entropy
-
DeepLab: FCN + CRF
-
CRF(Conditional random field):
-
Energy function: $$ E(x)=\sum_{i'}\theta_i(x_i)+\sum_{ij}\theta_{ij}(x_i,x_j) $$
-
Unary potential $$ \theta_i(x_i)=-\log P(x_i) $$
-
Pairwise potential $$ \begin{aligned}\theta_{ij}(x_{i},x_{j})=&\mu(x_{i},x_{j})\bigg[w_{1}\exp\bigg(-\frac{||p_{i}-p_{j}||^{2}}{2\sigma_{\alpha}^{2}}-\frac{||I_{i}-I_{j}||^{2}}{2\sigma_{\beta}^{2}}\bigg)\newline &+w_{2}\exp\Big(-\frac{||p_{i}-p_{j}||^{2}}{2\sigma_{\gamma}^{2}}\Big)\Big]\end{aligned} $$ where \(\mu(x_{i},x_{j})=1\) if \(x_i\neq x_{j}\), and zero otherwise
-
-
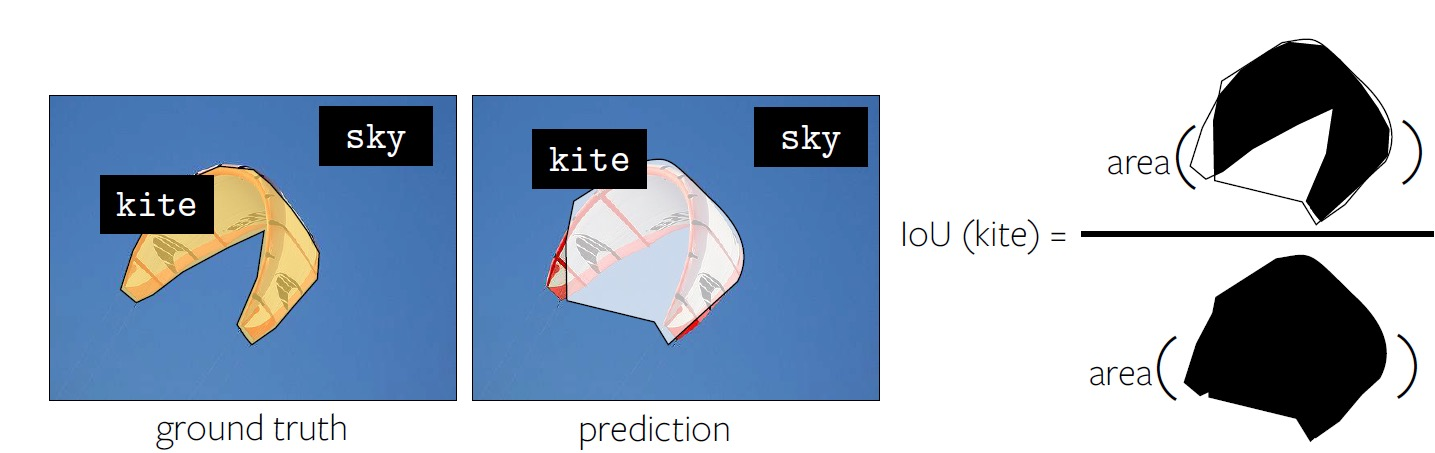
Evaluation metric: Per-pixel Intersection-over-union(IoU)
Object detection¶
-
output: a set of bounding boxes that denote objects
-
detect a single object: Treat localization as a regression problem! 分两个网络进行分类和确定box范围
-
Region proposals:对图像采取过分割,找到所有有可能的box,通常基于启发式。relatively fast to run
- Selective Search gives 2000 region proposals in a few seconds on CPU
-
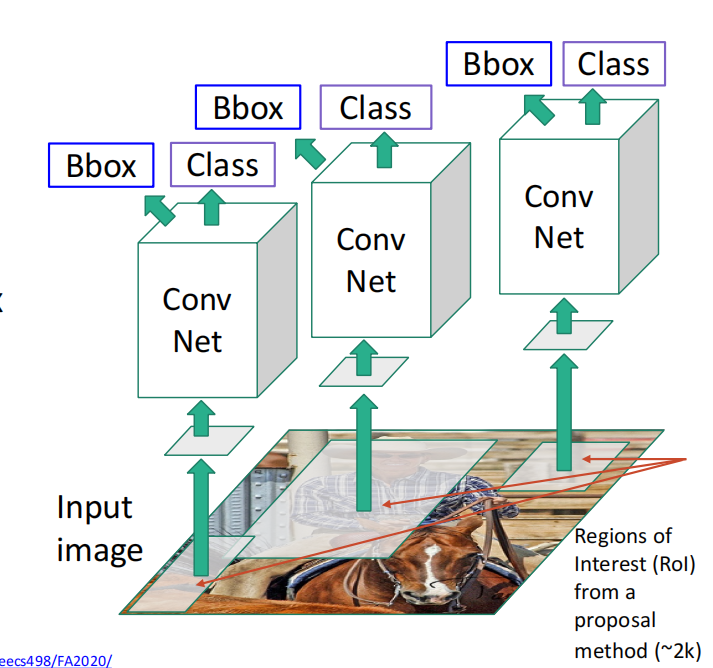
R-CNN
- Resize each region to 224x224 and run through CNN
- Predict class scores and bbox transform
- Use scores to select a subset of region proposals to output
- evaluation metric: IoU > 0.5 is decent, > 0.7 is pretty good, > 0.9 is almost perfect
- Non-Max Suppression: Object detectors often output many overlapping detections
- Select the highest-scoring box
- Eliminate lower-scoring boxes with IoU > threshold 和第一步中分数最高的计算IoU
- If any boxes remain, goto 1
-
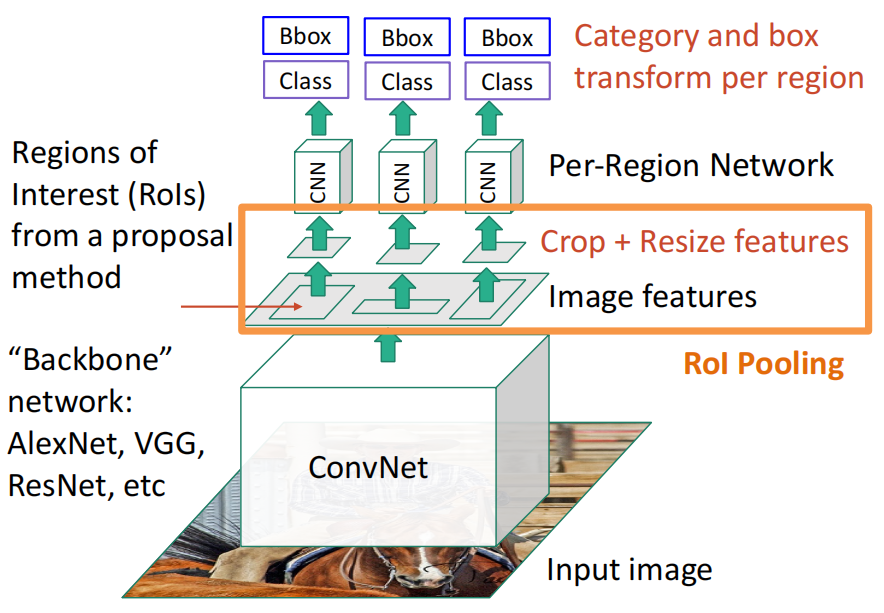
Fast R-CNN: 把整个图都跑一遍网络的backbone以提取特征,提高效率
-
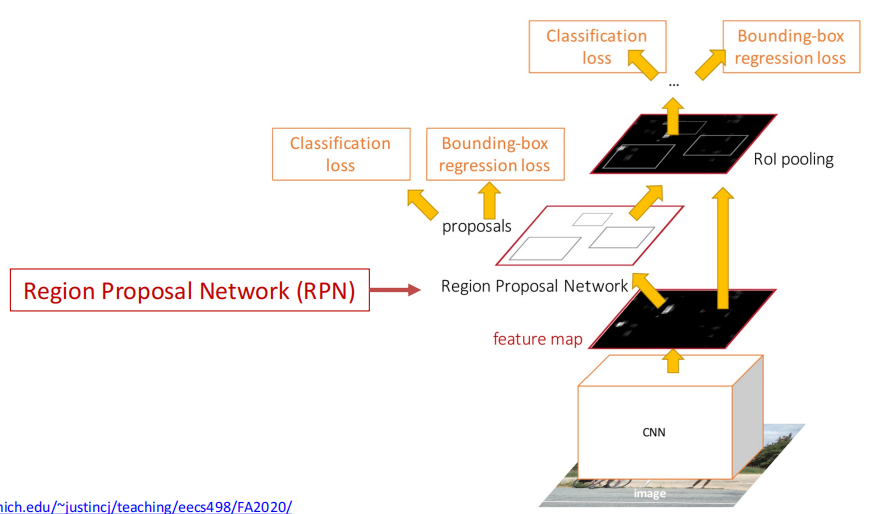
Faster R-CNN: A two-stage object detector
- First stage: run once per image
- Backbone network
- RPN
- Second stage: run once per region
- Crop features: RoI pool / align
- Predict object class
- Predict bbox offset
- 进一步地,使用一个卷积网络训练region proposal
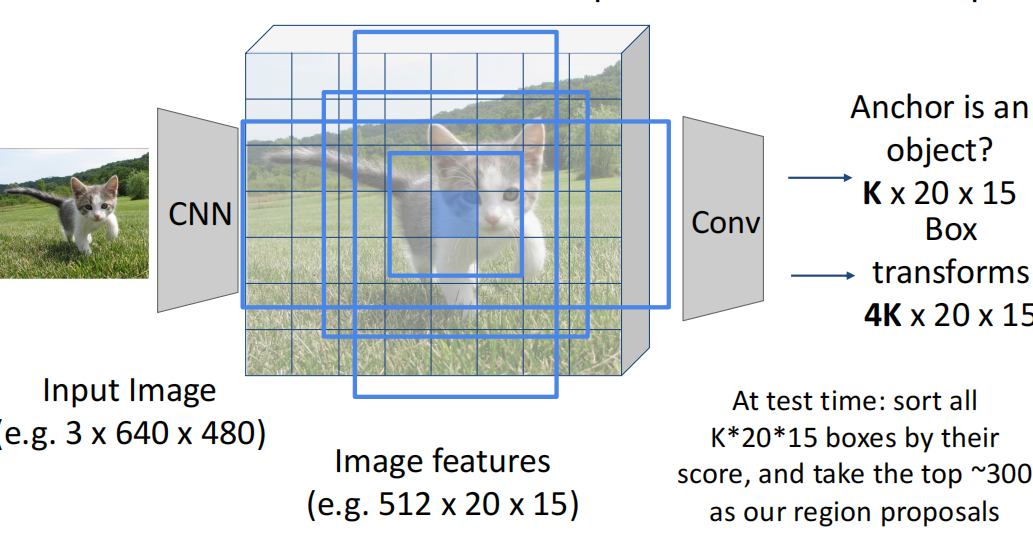
- RPN:预先定义K种可能的anchor box,对每个点都生成对应的这些box,之后跑网络,网络输出对应box是否包含物体,以及4个\(\Delta\),表示box在四个方向上要如何调整。最后选取分数最高的若干个
-
确认哪些box有object后,Single-Stage Detector: Classify each object as one of C categories (or background)
-
YOLO: single-stage。 即识别框内有物体和是什么物体只用跑一次,现在yolo用的最多
-
two vs. single
- Two-stage is generally more accurate
- Single-stage is faster
Instance segmentation¶
-
Faster R-CNN + additional head(mask prediction)
-
deep snake:最早的,通过优化的方式
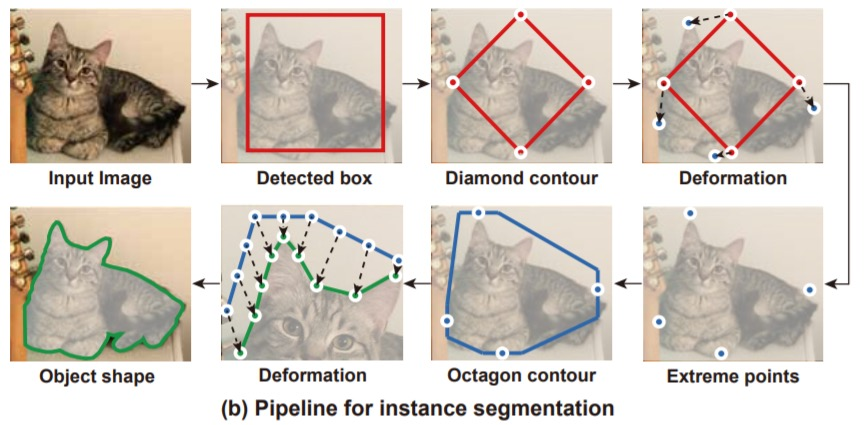
-
Beyond instance-segmentation
- Label all pixels in the image (both things and stuff)
Human pose estimation¶
- represent the pose of a human by locating a set of keypoints
e.g. 17 keypoints:
- Nose
- Left / Right eye
- Left / Right ear
- Left / Right shoulder
- Left / Right elbow
- Left / Right wrist
- Left / Right hip
- Left / Right knee
- Left / Right ankle
-
single human
- directly predict joint locations
- represent joint locations as the heatmap
-
Multiple humans
- Top-down: Detect humans and detect keypoints in each bbox 先用前面的方法分割找到每个人,之后再当single human识别。但效率低,同时两个人重合时可能只会有一个box,不可修正
- Mask R-CNNs
- 大部分的时候更准确
- Bottom-up: Detect keypoints and group keypoints to form humans
- Example: OpenPose: Link parts based on part affinity fields
- 更快,复杂情况效果可能更好
- Top-down: Detect humans and detect keypoints in each bbox 先用前面的方法分割找到每个人,之后再当single human识别。但效率低,同时两个人重合时可能只会有一个box,不可修正
Other tasks¶
- video classification: use 3D CNN
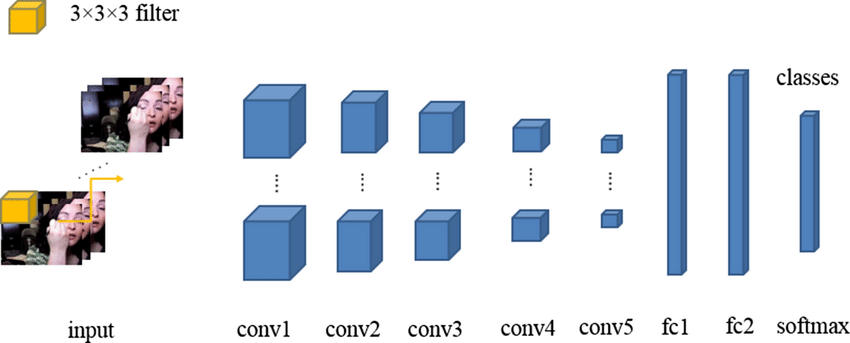
-
temporal action localization: Given a long untrimmed video sequence, identify frames corresponding to different actions 位置+帧的region propsal
-
Spatial-temporal detection: Given a long untrimmed video, detect all the people in space and time and classify the activities they are performing
-
Multi-object trackinig: Identify and track objects belonging to one or more categories without any prior knowledge about the appearance and number of targets.